依存语法ACL论文笔记(2)
依存语法ACL论文笔记(2)
依存语法ACL论文笔记(2)
Extended Topic Model for Word Dependency
主题模型假设词之间相互独立,该文提出一种模型对词之间的相关性进行建模。Topic Model such as Latent Dirichlet Allocation(LDA) makes assumption that topic assignment of different words are conditionally independent. Proposes a new model Extended Global Topic Random Field (EGTRF) to model non-linear dependencies between words.
假设词的主题受到距离为1,2的临近词的影响。Parse sentences into dependency trees and represent them as a graph, and assume the topic assignment of a word is influenced by its adjacent words and distance-2 words
模型首先对文章中的句子解析成依存树,然后扩展成为图的形式,一个简单的例子如下。
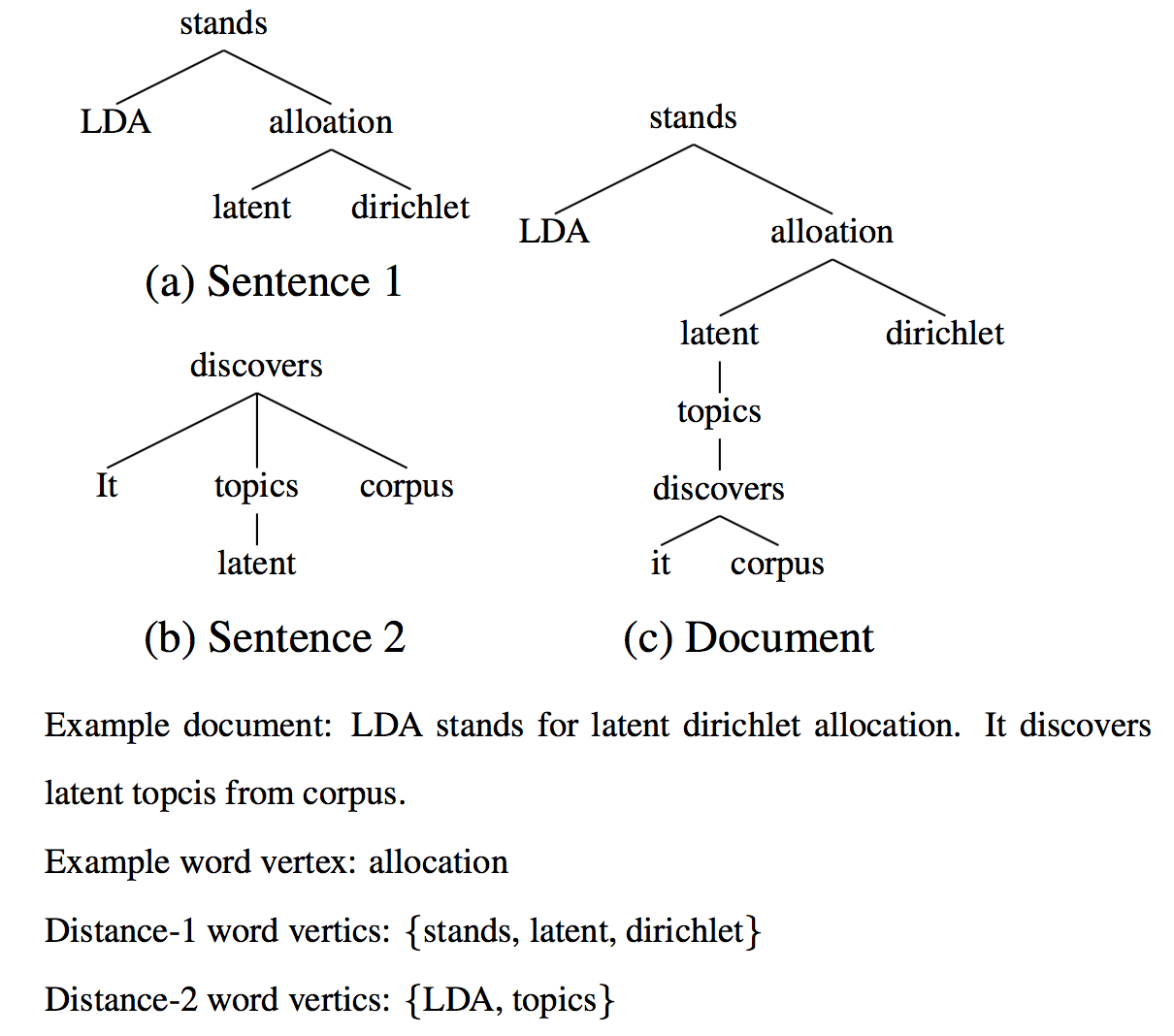
此外,该模型同时考虑到词表征特征(词嵌入)。Another advantage of EGTRF is it incorporates word features. The word vector representations are very interesting because the learned vectors explicitly encode many linguistic regularities and patterns (Mikolov et al, 2013).
基于图模型,对Global Random Field进行改进,提出算法Extended Global Random Field。类似主题模型,假设文章包含多个主题,每个词从主题中进行抽样,同时也从图结构中进行抽样。

考虑到图模型中词与词之间边的关系,从图结构的抽样的条件概率计算如下。
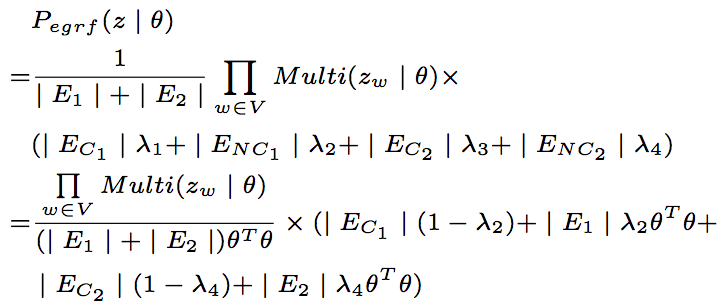
It Depends: Dependency Parser Comparison Using A Web-based Evaluation Tool
该文提出一种基于web的依存语法分析器评价工具。It can be difficult for a non-expert to select a good “off-the-shelf” parser. Developed a new web-based tool that gives a convenient way of comparing dependency parser outputs.
通常,对于依存语法分析器的评价指标包括一下几个:
- labeled attachment score (LAS): the percentage of predicted dependencies where the arc and the label are assigned correctly
- unlabeled attachment score (UAS): where the arc is assigned correctly
- label accuracy score (LS): where the label is assigned correctly
- exact match (EM): the percentage of sentences whose predicted trees are entirely correct
此前,对于依存语法的评价均基于Penn Treebank,因此不够全面。
文本评价数据基于OntoNotes 5。A large multi-lingual, multi-genre corpus annotated with syntactic structure, predicate- argument structure, word senses, named entities, and coreference (Weischedel and others, 2011; Pradhan and others, 2013).
本文使用的依存转化器比较如下。

本文使用的依存文法解析器如下。

本文的主要工作是开发了一个基于web的依存语法分析器评价工具。Recently, there is momentum towards web-based tools for annotation and visualization of NLP pipelines (Stenetorp and others, 2012). For this work, we used a new web-based tool, DEPENDABLE(Web-based Evaluation and Visualization Tool)。
其主要功能Feature如下。
- It reads any type of Tab Separated Value (TSV) format, including the CoNLL formats.
- It computes LAS, UAS and LS for parse out- puts from multiple parsers against gold (manual) parses.
- It computes exact match scores for multiple parsers, and “oracle ensemble” output, the upper bound performance obtainable by com- bining all parser outputs.
- It allows the user to exclude symbol tokens, projective trees, or non-projective trees.
- It produces detailed analyses by POS tags, de- pendency labels, sentence lengths, and de- pendency distances.
- It reports statistical significance values for all parse outputs (using McNemar’s test).
可视化截图和准确率比较如下。



相关连接