Knowledge-bases and Crowdsourcing
KATARA: A Data Cleaning System Powered by Knowledge Bases and Crowdsourcing
数据清洗是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。
通过数据清洗解决的问题包括但不限于:
- 数据的完整性
- 数据的唯一性
- 数据的权威性
- 数据的合法性
- 数据的一致性
传统的数据清洗主要依靠数据的完整性约束,并基于统计和机器学习算法进行(缺少了人的主动参与)。知识库系统(结合众包)给数据清洗提供了新的思路和机遇。
Classical approaches to clean data have relied on using integrity constraints, statistics, or machine learning. These approaches are known to be limited in the cleaning accuracy, which can usually be improved by consulting master data and involving experts to resolve ambiguity. The advent of knowledge bases (kbs), both general-purpose and within enterprises, and crowdsourcing marketplaces are providing yet more opportunities to achieve higher accuracy at a larger scale.
采用知识库系统(结合众包)进行数据清洗主要存在以下挑战,主要体现在脏数据匹配、知识库不完整、人的主动参与3个方面。
- Matching (dirty) tables to kbs is a hard problem. Tables may lack reliable, comprehensible labels, thus requiring the matching to be executed on the data values. This may lead to ambiguity; more than one mapping may be possible.
- kbs are usually incomplete in terms of the coverage of values in the table, making it hard to find correct table patterns and associate kb values.
- Human involvement is needed to validate matchings and to verify data when the kbs do not have enough coverage.
Katara是采用知识库系统(结合众包)进行数据清洗的首次尝试,其主页如下。
http://da.qcri.org/ntang/dcprojects/katara.html
Katara首先从已有数据中发现表模式(table patterns)映射到知识库,进行众包支持和检验,还支持脏数据修复。
Present Katara, the first data cleaning system that leverages prevalent trustworthy kbs and crowd-sourcing for data cleaning. Given a dirty table and a kb, Katara first discovers table patterns to map the table to the kb. With table patterns, Katara annotates tuples as either correct or incorrect by interleaving kbs and crowdsourcing. For incorrect tuples, Katara will extract top-k mappings from the kb as possible repairs.
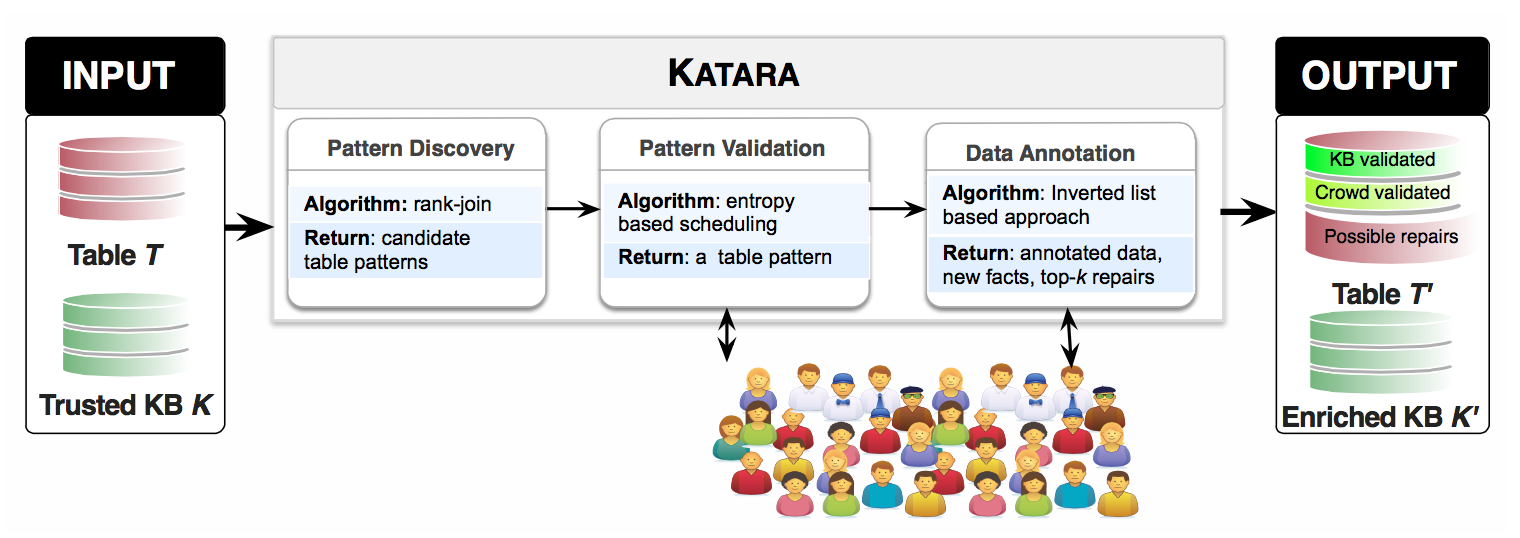
Overview
Katara主要包括三个模块:模式发现、模式检验和数据标注。
Katara consists of three modules pattern discovery, pattern validation, and data annotation. The pattern discovery module discovers table patterns between a table and a kb. The pattern validation module uses crowdsourcing to select one table pattern. Using the selected table pattern, the data annotation module interacts with the kb and the crowd to annotate data. It also generates possible repairs for erroneous tuples.
Katara的整体框架和数据流如下。
Preliminaries
首先对Katara中用到的术语进行描述。
表模式是指表的列所构成的有向关系图。
Table pattern. A table pattern (pattern for short) phi of a table T is a labelled directed graph G(V,E) with nodes V and edges E.
语义是指知识库中实体关系对表模式的映射。
Semantics. A tuple t of T matches a table pattern phi containing m nodes {v1,..,vm} w.r.t. a kb K, denoted by t |= phi, if there exist m distinct attributes {A1,...,Am} in T and m resources {x1,...,xm} in K such that:

部分映射只是上诉映射条件中2和3至少满足其一。
We say that a tuple t of T partially matches a table pattern phi w.r.t. K, if at least one of condition 2 and condition 3 holds.
下图说明了Katara中表模式和关系库映射的关系,针对未涵盖的属性,可以采用众包的方式进行补足。
Given a table T, a kb K, and a pattern phi, the following figure shows how Katara works on T. For non-covered attributes, could ask the crowd open-ended questions.
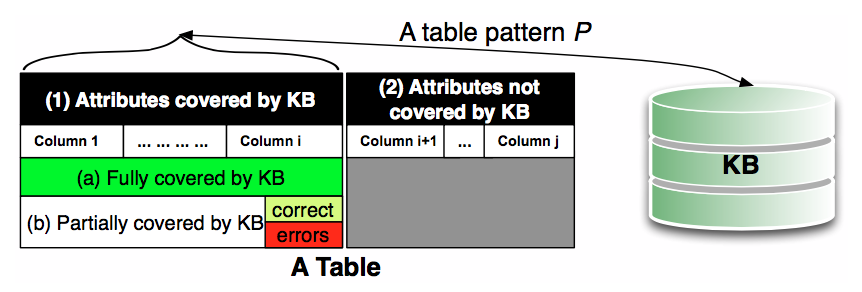
Table Pattern Discovery
下面描述表模式发现。
Candidate Type/Relationship Discovery
首先需要生成类型和关系的候选集,采用了SPARQL查询语言。
Issue the following SPARQL query which returns the types and supertypes of entities whose label (i.e., value) is t[Ai].

Similarly, the relationship between two values t[Ai] and t[Aj] from a kb K can be retrieved via the two following SPARQL queries.

Query Q1rels retrieves relationships where the second attribute is a resource in kbs and Q2rels retrieves relationships where the second attribute is a literal value, i.e., untyped.
之后采用正规化后的tf-idf对列类型进行排序。
Use a normalized version of tf-idf (term frequency-inverse document frequency) to rank the candidate types of a column Ai.
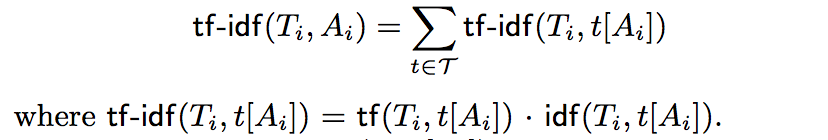
Scoring Model for Table Patterns
第二步需要对可能的模式进行排序(降低人工验证的成本)。
A table pattern contains types of attributes and properties between attributes. The space of all candidate patterns is very large (up to the Cartesian product of all possible types and relationships), making it expensive for human verification.
一种朴素的打分方法是将所有类型匹配得分和关系匹配得分进行求和。
A naive scoring model for a candidate table pattern phi, consisting of type Ti for column Ai and relationship Pij for column pair Ai and Aj, is to simply add up all tf-idf scores of the candidate types and relationships in phi:
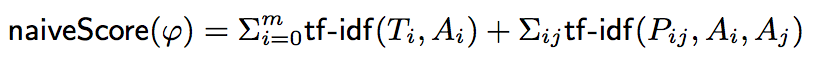
采用点互信息(pointwise mutual information)计算匹配度。
To quantify the "compatibility" between a type T and relationship P, where T serves as the type for the resources appearing as subjects of the relationship P, introduce a coherence score subSC(T,P). Similarly, to quantify the "compatibility" between a type T and relationship P, where T serves as the type for the entities appearing as objects of the relationship P, introduce a coherence scores objSC(T,P).
Use pointwise mutual information (PMI) as a proxy for computing subSC(T,P) and objSC(T,P).
公式如下。
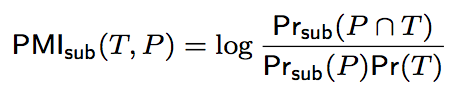
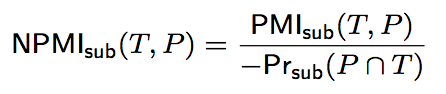
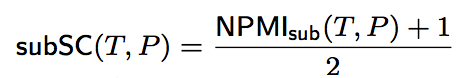
总得分计算公式如下。
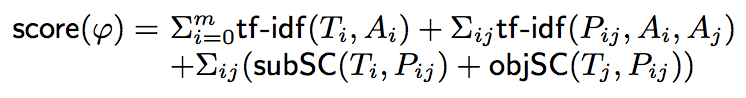
Top-k Table Pattern Generation
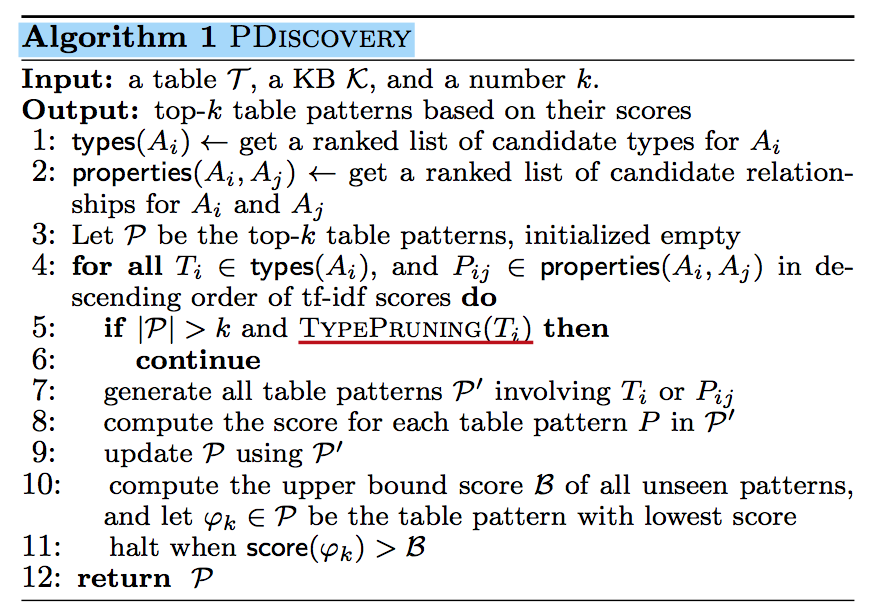
Top-k个表模式生成算法如下,主要在于早终止算法的设计(全部候选模式可能成指数型增长)。
Given a set of sorted lists and join conditions of those lists, the rank-join algorithm produces the top-k join results based on some score function for early termination without consuming all the inputs.
算法的详细描述如下。
The algorithm, referred as PDiscovery. Given a table T, a kb K, and a number k, it produces top-k table patterns. To start, each input list, i.e., candidate types for a column, and candidate relationships for a column pair, is ordered according to the respective tf-idf scores. When two candidate types have the same tf-idf scores, the more discriminative type is ranked higher, i.e., the one with less number of instances in K.

Pattern Validation via Crowd
下面描述表模式的众包检验方法,主要在于对问题顺序进行优化,减少回答问题数量所导致的人工成本。
Now study how to use the crowd to validate the discovered table patterns. Specifically, given a set P of candidate patterns, a table T, a kb K, and a crowdsourcing framework, need to identify the most appropriate pattern for T w.r.t. K, with the objective of minimizing the number of crowdsourcing questions.
Creating Questions for the Crowd
可将表模式检验拆分为如下的两个子问题,即类型检验和二元关系检验。
- type validation, i.e., to validate the type of a column in the table pattern.
- binary relationship validation, i.e., to validate the relationship between two columns.
Column type validation
类型检验的提问方式如下。

Relationship validation
关系检验的提问方式如下。

Question Scheduling
减少回答问题数量所导致的人工成本,需要对问题顺序进行优化,算法描述如下。
Algorithm 3 describes the overall procedure for pattern validation.
- choose the best variable vbest to validate next based on the expected reduction of uncertainty of phi.
- remove from Pre those table patterns that have a different assignment for variable v than the validated value a.
- renormalize the probability distribution of the remaining table patterns in Pre.
- terminate when there are left with only one table pattern.

Data Annotation
最后是数据标注(包括数据修复)。
Annotating Data
数据标注过程结合了知识库系统和众包,过程分为两步,描述如下。
- Step 1: Validation by kbs. For each tuple t and pattern phi, Katara issues a SPARQL query to check whether t is fully covered by a kb K. If it is fully covered, Katara annotates it as a correct tuple validated by kb (case (i)). Otherwise, it goes to step 2.
- Step 2: Validation by kbs and Crowd. For each node (i.e., type) and edge (i.e., relationship) that is missing from K, Katara asks the crowd whether the relationship holds be- tween the given two values. If the crowd says yes, Katara annotates it as a correct tuple, jointly validated by kb and crowd (case (ii)). Otherwise, it is certain that there exist errors in this tuple (case (iii)).
Generating Top-k Possible Repairs
同时针对脏数据提供了Top-k种可能的修复方法。
A natural way to improve the naive solution for top-k possible repair generation is to retrieve only instance graphs that can possibly be repairs, i.e., the instance graphs whose values have an overlap with a given erroneous tuple.
优化算法如下。
The optimized algorithm is as follows. All possible repairs are initialized and instantiated by using inverted lists. For each possible repair, its repair cost w.r.t. t is computed, and top-k repairs are returned.

相关连接
- https://cs.uwaterloo.ca/~ilyas/papers/ChuSIGMOD2015.pdf