Data Labeling in Knowledge Base Construction
Mindtagger: A Demonstration of Data Labeling in Knowledge Base Construction
知识库是用于知识管理的一种特殊的数据库,以便于有关领域知识的采集、整理以及提取。知识库中的知识源于领域专家,它是求解问题所需领域知识的集合,包括基本事实、规则和其它有关信息。
DeepDive是Stanford开发的自动化知识库构建系统,主要通过统计学习、推理系统从多源数据中抽取知识。
DeepDive虽然能够以自动化的方法构建知识库系统,但在调试和系统优化方面存在不足和挑战。
As a result of deploying DeepDive framework across several domains, new challenges are found in debugging and improving such end-to-end systems to construct high-quality knowledge bases.
To help users, it is needed to develop principles for analyzing the system’s error as well as provide tooling for inspecting and labeling various data products of the system.
在调试和系统优化方面存在的不足主要在于,难以从现有的系统输出直接反应出系统内部所存在的问题,从而有针对性的对系统进行优化(例如系统所包含的众多模块对外部都视为黑箱,因此难以从最终结果推测可能存在问题的模块和具体的问题,因此难以对症下药的对系统相关参数进行调节),同时模块的复杂性和模块之间的相互作用更加加深了问题的挑战。
为了能够帮助用户对系统所存在的问题进行定位和排查,优化现有系统,Mindtagger的存在具有普遍意义。Mindtagger能够针对系统的不同模块的输出结果进行人工标注,并通过标注结果进行分析,对问题进行分类并制定相应的解决方案。
To enable more productive and systematic data labeling, Mindtagger was created, a versatile tool that can be configured to support a wide range of tasks.
目前,DeepDive和Mindtagger相结合,已经应用到许多不同的场景。
Several groups in different domains are using DeepDive and Mindtagger to construct high-quality knowledge bases: paleo-biology, genomics, pharma domains, intelligence, lawenforcement, and material science.
为了构建知识库系统,DeepDive首先从文本中抽取出实体和实体间关系,之后经过统计、推理,与已有知识库系统融合(可理解为宽展和去噪)形成自己的知识库体系。
DeepDive作为一个典型的端到端知识库系统,包含了许多相互关联的模块,并最终输出构建出的知识库。
End-to-end knowledge base construction (KBC) systems using statistical inference are enabling more people to automatically extract high-quality domain-specific information from unstructured data.
A wide range of data processing components are put together in the system: crawlers pull in large amounts of unstructured text and image data from various sources; ETL (extract, transform, and load) components clean the raw data and add natural language processing markups to the text; an array of extractors extract candidate mentions of entities and relationships along with their features; an inference engine constructs and trains a probabilistic model from the data to predict probabilities of the extracted information; finally, a search engine surfaces such information to law enforcement personnel.
Challenges
Principled Error Analysis
很多时候,我们需要对端到端系统的每一个模块进行调试,但调试结果却只能反映在系统最终的输出,这个环节牵扯到许多其他模块,因此对调试带来了很大挑战。
In many cases, colleagues were tempted to examine only a small sample of errors and to use their intuition and luck to fix whichever attractive ones they encountered.
为了解决这个问题,Mindtagger提供了针对模块粒度的调试功能。
Mindtagger created guidelines for error analysis that help users identify possible improvements and assess their potential impact in a principled way.
Productive Data Labeling
为了对系统进行调试,对所存在的问题进行标注和分类成为重点之一。
Lack of tooling for inspecting and labeling data products of the system under development was slowing down every iteration of the development cycle. In every step of error analysis guidelines, data labeling plays a key role.
Mindtagger提供了交互式、可视化的标注功能、
To enable more productive data labeling and to study unanticipated types of labeling tasks involved in the actual error analysis, Mindtagger was created, an interactive graphical tool for labeling data.
与Mindtagger相似的包含人工参与环节的系统还有Data Tamer和Trifacta等,但与此不同,Mindtagger能够针对每个环节进行标注而不仅限于统计推断环节。
Innovative systems such as Data Tamer and Trifacta are making human involvement more productive in data integration, cleaning, and transformation, but Mindtagger is richer in the sense that end-to-end KBC systems typically handle those problems as part of the statistical inference.
Variable Data Products and Labeling Tasks
系统所需要的标注和审查随模块的不同存在差异。
The data to be inspected as well as the detail of necessary labeling tasks constantly vary as development progresses.
Mindtagger提供了针对不同模块的标注和审查功能,具有良好的可重用性和可扩展性。
Mindtagger support a wide range of tasks and data types by mixing and matching predefined configuration fragments so that the task configurations could be easily reused and extended.
System Overview
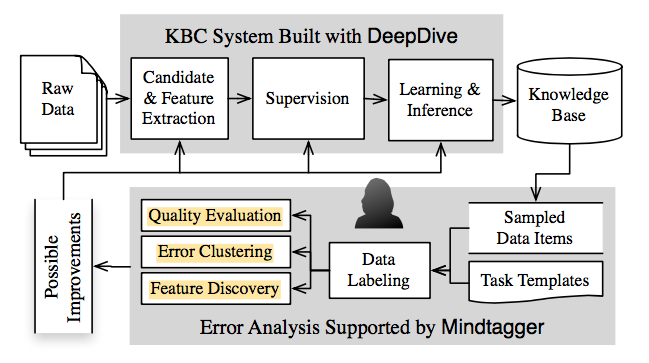
Mindtagger整体系统框图如下。
Mindtagger is an interactive data labeling tool we created to help DeepDive users perform error analysis in more systematic and productive ways.
Mindtagger输入一系列数据,以及定义数据展现和交互方式的模板。
Mindtagger takes as input a list of data items and a template that defines the presentation of, and possible interactions with the items and provides a graphical user interface for annotating labels while browsing them.
Mindtagger是包含了错误分析的闭环系统。
Figure 1 shows where Mindtagger and the error analysis steps it supports fit into the overall iterative development cycle of an end-to-end knowledge base construction system.
Mindtagger支持从预设模式(准确率、回收率、审查等)中自定义数据标注方式。
Mindtagger can be easily configured to support a wide range of data labeling tasks by customizing one of its predefined modes: precision, full markup recall, quick check recall, and inspection mode, some of which are shown in Figure 2.

Demonstration Details
Mindtagger的实现细节如下。
A small part of a hypothetical knowledge base construction system is used to demonstrate how Mindtagger supports the data labeling tasks necessary for a full error analysis cycle. It boils down to following these three steps after every iteration:
Mindtagger的错误分析包含如下的迭代步骤:准确率、收回率估计;错误分类;错误样例审查。
- Evaluate the precision and/or recall of the extractions by identifying errors from a sample of the data product.
- Inspect and cluster the errors with their immediate details, such as extracted features.
- Explore extra data products relevant to the most common errors to develop concrete ideas for improvement.
Phone Number Extraction Example
下面以电话号码抽取为例,说明了Mindtagger的工作原理。
It is assumed that the information extraction is done using a simple binary classifier, and the following four components are in the system:
- Candidate Extraction. A basic candidate extractor scans the full text of the web pages with a set of simple regular expressions and emits matching text-spans that are likely to be phone numbers.
- Feature Extraction. Then a feature extractor collects words and phrases appearing near each candidate as its features for classification.
- Supervision. Instead of manually curating a training set, a program with a set of rules collects candidates as positive training examples that appear in a sentence that contains words highly likely to appear next to phone numbers, such as "call", "phone" or "contact".
- Inference. Finally, the binary classifier uses logistic regression to learn and predict whether the text-span is a phone number or not.
Evaluating Precision
Mindtagger的错误分析包含了准确率估计。
The estimated precision is simply the ratio of the number of true positives to the total number of samples examined.
Evaluating Recall
Mindtagger的错误分析包含了收回率估计,收回率估计要难于准确率估计,原因在于无法准确知道第二类错误的数量。因此,Mindtagger提供了两种模式,即Full markup mode和Quick check mode来对数据进行审查和标注。
Estimating recall is slightly more challenging than precision, as it’s about the unseen part of the data. The foremost objective of evaluating recall is to discover false negatives from the samples drawn from the entire corpus, not from the output of the extractor or classifier. The estimated recall is then the reciprocal of 1 + the relative size of false negatives to true positives in the sample.
- Full markup mode is designed for carefully identifying all mentions appearing in sampled documents.
- Quick check mode is for tagging whether a sentence or paragraph simply contains a mention or not.
Inspecting Errors
Mindtagger的错误分析包含了错误审查功能,使得能够针对标注为不同类型的错误分析出错原因并对系统进行修正。
It is assumed that the attendee wants to improve the extraction quality after evaluating precision and recall, although error analysis in general can stop here when the measures are satisfactory. She now has to understand the cause for each error found in the previous steps in order to cluster them and focus on the most common type.
The attendee browses the errors partially labeled with their causes in Mindtagger’s inspection mode using the configuration below. She can add her own labels to the text mistaken as phone numbers, such as "part of URL" or "part of product code", which hints at how the regular expressions should be tuned or what new features should be extracted.
Calibrating Supervision
为了对系统修正结果进行验证,通常需要对存在类似错误的样例进行审查,Mindtagger同样提供了此项功能。
To correct the inspected errors, it is often necessary to explore more data that share features with the errors to calibrate the supervision rules. False positives can be explained by features having spuriously high weights learned from a biased training set with little negative examples but too many positive ones. Taking a broader look at more candidates sharing such features helps in understanding which rules were overly supervising the candidates as positive training examples, or more importantly, what new rules could be created to turn some of the unsupervised candidates into negative training examples. Similarly, false negatives due to low-weighted features can be handled by calibrating the supervision rules to introduce more positive examples after examining other candidates sharing the features.
Using Mindtagger’s inspection mode, the attendee can reliably come up with new rules for negative training examples based on concrete observations.
相关连接
- http://cs.stanford.edu/people/chrismre/papers/p2148-shin-vldb-demo.pdf