Relation Extraction Algorithms
Relation Extraction Algorithms
Relation Extraction Algorithms
基于非结构化文本的实体关系抽取技术方法可以归纳为:基于模式匹配的关系抽取、基于词典驱动的关系抽取、基于机器学习的关系抽取、基于本体的关系抽取以及混合抽取方法。
其中,基于机器学习的抽取方法可以粗分为Supervised和Semi-supervised两种,下面具体介绍各种算法。
Feature based Methods (Supervised)
首先总结有监督的学习方法,重点是实体间的二元关系(binary relations),多元关系(N-ary relation)可以看成是二元关系的扩展。
For the sake of simplicity and clarity, only restrict to binary relations between two entities. N-ary relation extraction will be discussed later.
当给出一个句子S(字符序列),实体间关系的分类器可表达如下,其中,T(S)是S的特征,f是分类器,R是分类器的参数,我们需要学习的是参数R。
Given a sentence S = w1,w2,..,e1..,wj,..e2,..,wn, where e1 and e2 are the entities, a mapping function f(.) can be given as
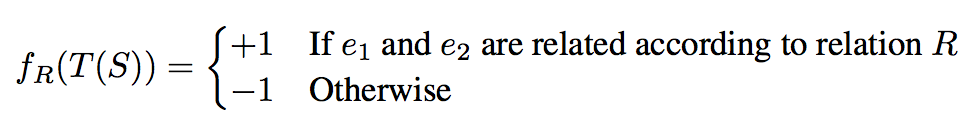
where T(S) are features that are extracted from S.
分类器/算法可以选择常用的有监督学习算法,例如神经元(Perceptron)、投票神经元(Voted Perceptron)或支撑向量机(Support Vector Machines)。分类器/算法的特征来自于文本分析,例如词性标注或依存树解析。
The function f(.) can be constructed as a discriminative classifier like Perceptron, Voted Perceptron or Support Vector Machines (SVMs). These classifiers can be trained using a set of features selected after performing textual analysis (like POS tagging, dependency parsing, etc) of the labeled sentences.
基于特征的方法所使用的句法特征通常包括一下几个方面,主要包括实体自身、实体类别、实体间的字符序列、实体间的字符数(距离)、在解析树中实体间的路径等。
- the entities themselves
- the types of the two entities
- word sequence between the entities
- number of words between the entities
- path in the parse tree containing the two entities
基于特征的方法中,特征的选取通常基于启发式算法或试错法来最大化分类准确率。
Feature based methods involve heuristic choices and the features have to be selected on a trial-and-error basis in order to maximize performance.
Bag of features Kernel (Supervised)
为了更好的利用特征,通常可采用核方法(人工定制)来挖掘特征间的关联。
To remedy the problem of selecting a suitable feature-set, specialized kernels are designed for relation extraction in order to exploit rich representations of the input data like shallow parse trees etc.
其中核的选取通常采用字符串核(string-kernels)。给出两个字符串,字符串核能够首先把每个字符串投射到高维核空间,计算其间的相似度,核空间的转换主要基于序列相似性。
The kernels used for relation-extraction (or relation-detection) are based on string-kernels described in (Lodhi et al., 2002). Given two strings x and y, the string-kernel computes their similarity based on the number of subsequences that are common to both of them. Each string can be mapped to a higher dimensional space where each dimension corresponds to the presence (weighted) or absence (0) of a particular subsequence.
投射到高维核空间的过程如下例。
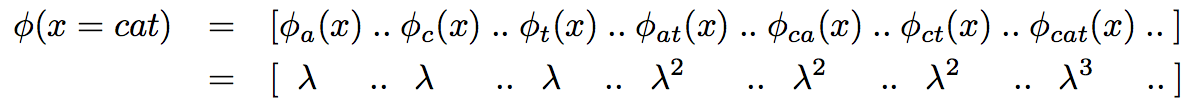
字符串核计算相似度的方法如下。
If U is the set of all possible ordered subsequences present in strings x and y, the kernel similarity between x and y is given by
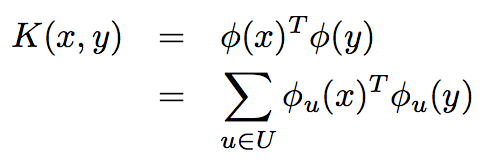
算法复杂度分析如下,如果直接计算,将会产生指数级的复杂度,为了优化,可以采用动态规划方法。
A straightforward computation involves exponential complexity. In practice however, the computation is performed implicitly in a efficient manner using a dynamic programming technique described in (Lodhi et al., 2002). The complexity of computation of the string-kernel is O(|x||y|2) (|x| ∏ |y|).
字符串核的相关内容可以参考这篇论文。
http://www.jmlr.org/papers/volume2/lodhi02a/lodhi02a.pdf
为了计算实体间的关系的相似性,可以通过提取句子(字符序列)中实体出现的位置前、中、后对应的字符(序列)作为特征,然后采用字符串核计算相似度。
A sentence s = w1, ..., e1, ..., wi, ..., e2, ..., wn containing related entities e1 and e2 can be described as s = sb e1 sm e2 sa. Here sb, sm and sa are portions of word-context before, middle and after the related entities respectively. Now given a test sentence t containing entities e01 and e02, the similarity of its before, middle and after portions with those of sentence s is computed using the sub-sequence kernel.
Bunescu等人提出分别基于实体出现的位置前、中、后对应的字符(序列)、词性、实体类别等特征,建立三个子(树)核分别计算相似度,然后加和起来。
Bunescu et. al. use three subkernels, one each for matching the before, middle and after portions of the entities context and the combined kernel is simply the sum of all the subkernels and augment the words in the context with their respective part-of-speech (POS) tags, entity types etc to improve over the dependency tree kernel approach.
Tree Kernels (Supervised)
树核(Tree Kernels)和之前的字符串核不同的是特征来自于解析树。从解析树中抽取特征的好处在于具有较好的鲁棒性和可靠性(因为文字序列的表达多种多样,但解析树的形式弱化了这种多样性)。
Compared to the previous approach, (Zelenko et al., 2003) replace the strings in the kernelwith structured shallow parse trees built on the sentence. The rationale for using shallow parse trees instead of full parse trees is that they tend to be more robust and reliable.
对于一个解析树,训练集中的正例是包含两个实体的最小子树,反例则不包含。针对两个子树,树核计算的是其树形结构上的相似性。
Now given a shallow parse, positive examples are constructed by enumerating the lowest subtrees which cover both the related entities. If a subtree does not cover the related entities, it is assigned a negative label. Given two shallow parse trees the kernel computes the structural commonality between them.
正反例的例子如下。
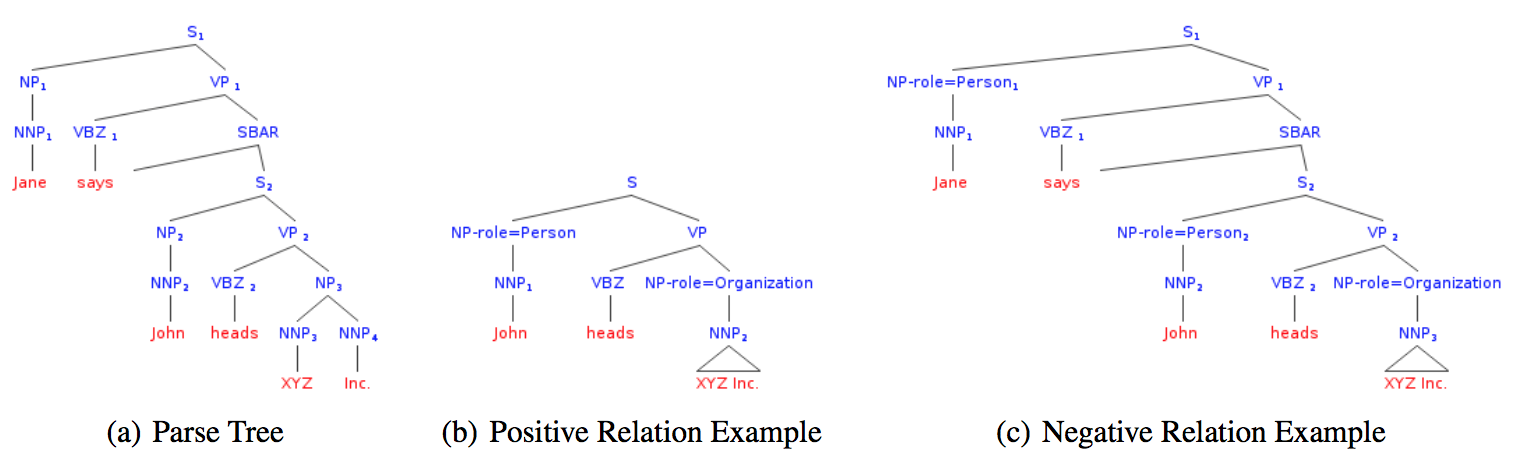
树核相似度的计算如下。

解析树中两实体间的路径P通过可以作为识别实体关系的特征。
The shortest path between the two entities in a dependency parse encodes sufficient information to extract the relation between them. If e1 and e2 are two entities in a sentence and p their predicate, then the shortest path between e1 and e2 passes through p. Let one such path be P = e1 → w1 .. → wi ← .. ← wn ← e2.
但由于数据的稀疏性,仅依靠路径P效果不佳,因此可以考虑采用词性等作为特征,计算笛卡尔积,降低数据的稀疏性。
Using P alone as a feature would lead to bad performance due to data sparsity. Therefore word-classes like POS are extracted from each of the words and the feature vectors is given by a Cartesian product as
笛卡尔积的计算如下。
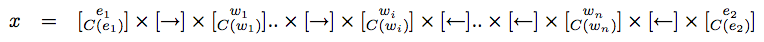
DIPRE (Semi-supervised)
半监督方法的一致思路是,首先采用弱分类器标注得到更多的数据,再将其补充进训练集用于下一轮迭代。
The main idea of both algorithms is to use the output of the weak learners as training data for the next iteration.
协同训练(co-training algorithm)是一种常用的半监督方法(例如可以从文法和语义两个维度分别建立子分类器进行协同训练),它需要满足两大约束:单个分类器效果要足够好,多个分类器的特征要条件独立。
To ensure provable performance guarantees, the co-training algorithm assumes as input a set of views that satisfies two fairly strict conditions. First, each view must be sufficient for learning the target concept. Second, the views must be conditionally independent of each other given the class.
DIPRE是一种典型的半监督方法,其算法描述如下。

The system crawls the Internet to look for pages containing both instances of the seed. To learn patterns DIPRE uses a tuple of 6 elements [order,author,book,prefix,su±x,middle]. The next step is to generalize the pattern with a wild card expression. DIPRE uses this pattern to search the Web again, and extract relations.
Snowball (Semi-supervised)
Snowball也是一种典型的半监督方法,相比于DIPRE,它将字符序列表示成元组的形式,增加了每个子序列的权重。
Snowball represents each tuple as a vector and uses a similarity function to group tuples.
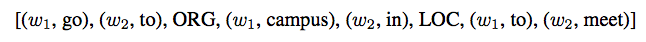
权重表示了该模式中该子序列出现的可能性,权重的计算如下。
Each wi is a term weight which is computed by the normalized frequency of that term in a given position. For example, term weight of token meet in the suffix is
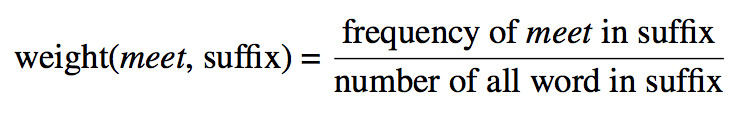
基于权重的相似度计算如下。
To group tuples which have the same (organization, location) representation but differ in prefix, suffix, and middle Snowball introduce the similarity function
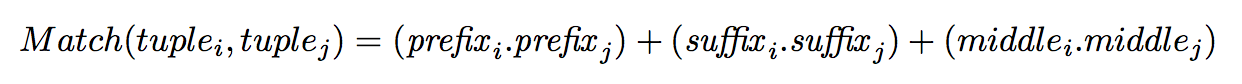
最后基于相似度进行分组,并为每个分组生成了一个模式,模式的置信度的计算如下。
After grouping tuples into classes, Snowball induces a single tuple pattern P for each class which is a centroid vector tuple. Each pattern P is assigned a confidence score which measure the quality of a newly-proposed pattern
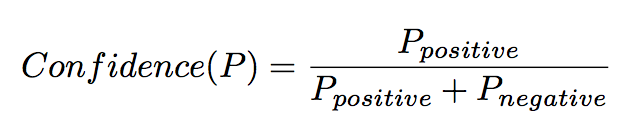
相比于DIPRE,由于增加了权重信息,因此具有更好的鲁棒性(并不要求每个字符和标点都完全一致)。
Compared to DIPRE, Snowball has a flexible matching system. Instead of having exact surface text matches, Snowball’s metrics allows for slight variations in token or punctuation.
KnowItAll and TextRunner (Semi-supervised)
KnowItAll和TextRunner也是两种典型的半监督方法,和之前的算法相比,其数据全部来源于Web,并自动标注模式。
Unlike DIPRE and Snowball, KnowItAll is a large scale Web IE system that labels its own training examples using only a small set of domain independent extraction patterns.
数据的获取基于规则,通过采用定制的搜索请求,获取和规则相关的数据(训练集)。
The rules are applied to web pages, identified via search-engine queries, and the resulting extractions are assigned a probability using pointwise mutual information (PMI) derived from search engine hit counts.
例如为了获取同类关系可以采用:"
DIPRE, Snowball, KnowItAll都用来获取特定领域(relation-specific)的知识,而TextRunner采用自监督(self-supervised)的方法获取实体关系。
DIPRE, Snowball, and KnowItAll are all relation-specific systems. Instead of requiring relations to be specified in its input, TextRunner learns the relations, classes, and entities from the text in its corpus in a self-supervised fashion.
TextRunner的架构和计算过程如下。
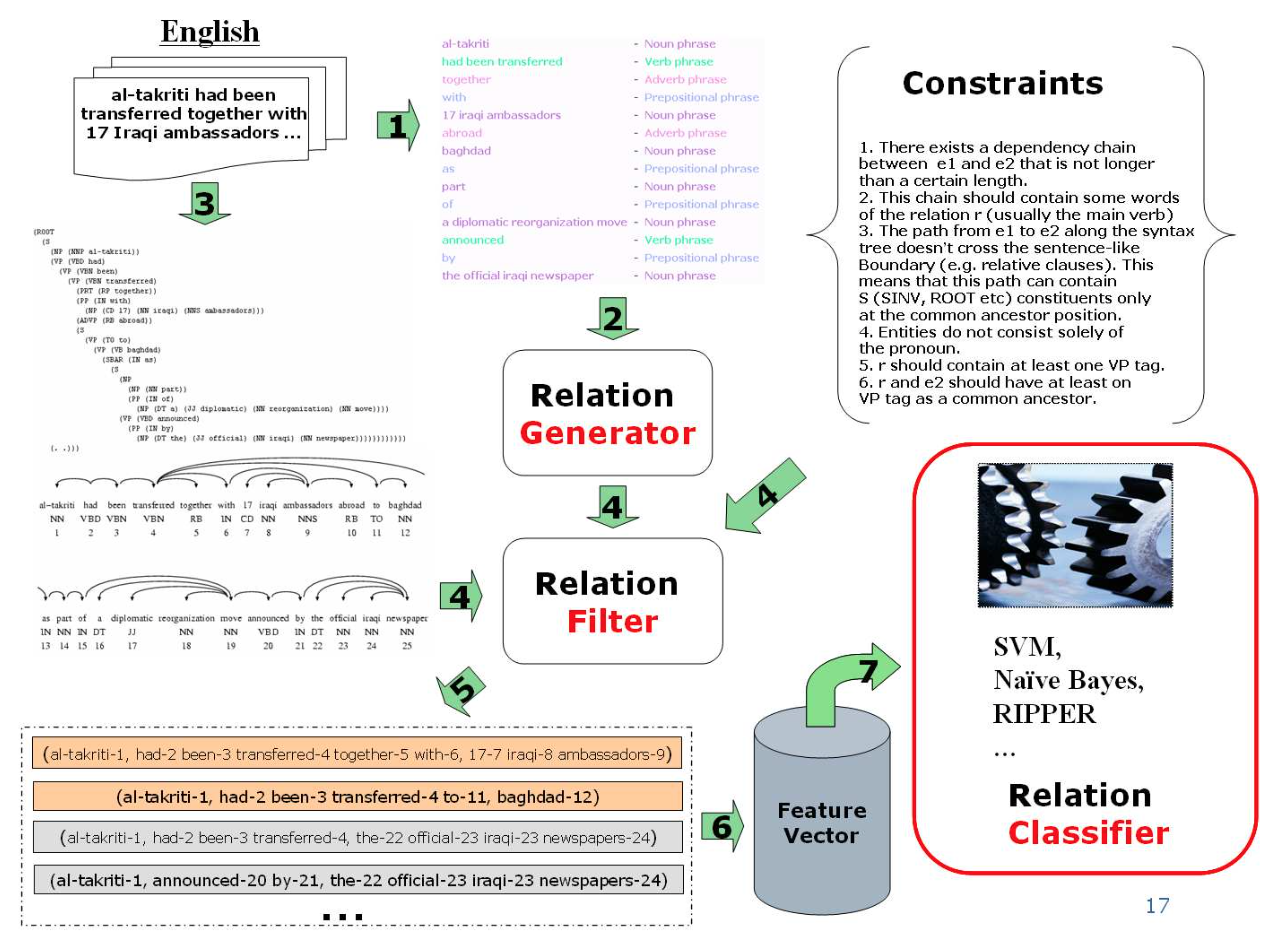
The Learner first automatically labeled its own training data as positive or negative, then it uses this labeled data to train a binary classifier which is used by Extractor. The Extractor generates one or more candidate relations from each sentence, then runs a classifier and retains the ones labeled as trustworthy relations. The Assesor assigns a probability to each retained tuple based on a probabilistic model of redundancy.
语法解析只发生在训练阶段,因此能够优化效率。
Parsers are only used once when the Learner performs its self-training process for the classifier. The key idea of the system is the Extractor extracts relations from a large amount of text without running the dependency parser.
Beyond Binary Relations
除了二元关系,很多应用还需要抽取多元关系。
For example, we are interested in the ternary relation (organizer, conference, location) that relates an organizer to a conference at a particular location. For a sentence “ACL-2010 will be hosted by CMU in Pittsburgh”, the system should extract (CMU, ACL-2010, Pittsburgh).
多元关系的抽取可以采用下面的方法,基于二元关系进行抽取。
- Start by recognizing binary relation instances that appear to be arguments of the relation of interest.
- Extracted binary relations can be treated as the edge s of graph with entity mention as nodes.
- Reconstruct complex relations by making tuples from selected maximal cliques in the graph.
Evaluating Relation-Extraction
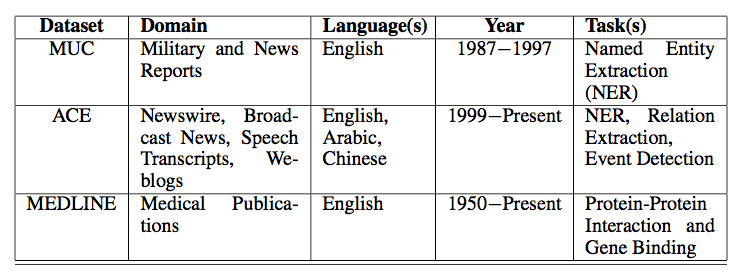
针对关系抽取算法的验证通常采用下面的训练集。
Datasets available for relation extraction evaluation.
评价指标如下。
Evaluation in Supervised Methods
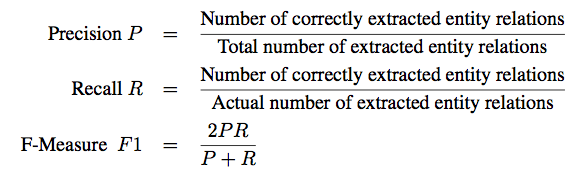
Evaluation of Semi-supervised Methods
通常在标注数据较少的情况下可以采用采样的方法对准确率进行估计。
A small sample drawn randomly from the output is treated as a representative of the output and manually checked for actual relations. Since the actual number of entity relations are difficult to obtain from large amounts of data, it is difficult to compute recall to evaluate semi-supervised methods.
相关连接
- http://www.cs.cmu.edu/~nbach/papers/A-survey-on-Relation-Extraction.pdf