Word2vec源码分析
Word2vec源码分析
Word2vec为一类双层神经元网络,用来产生词嵌入的模型。在bag-of-words的假设下,词的顺序是不重要的,通过训练,word2vec 模型可用来映射每个词到一个高维向量,可用来表示词对词之间的关系,例如用余弦相似度计算词与词之间的距离。
Word2vec的实现主要包括continuous-bag-of-words(CBOW)和skip-grams两种,其区别在于神经元网络结构的输入和输出对调。
Word2vec的源码地址为:
http://code.google.com/p/word2vec/
类似的词嵌入模型和算法还有GloVe等,地址为:
http://nlp.stanford.edu/projects/glove/
据说经测评,GloVe比Word2vec更胜一筹,但由于Word2vec先于GloVe出现,应用更为主流。
Word2vec原理解释
词袋模型(BOW),通过将重复的词叠加,以此来增加句子的似然概率。它基于朴素贝叶斯的独立性假设,将不同位置出现的相同词视为等价的,无视语义、语法等关联性。在单输入单输出的情况下(可视为窗口大小为1),神经元网络结构如下。
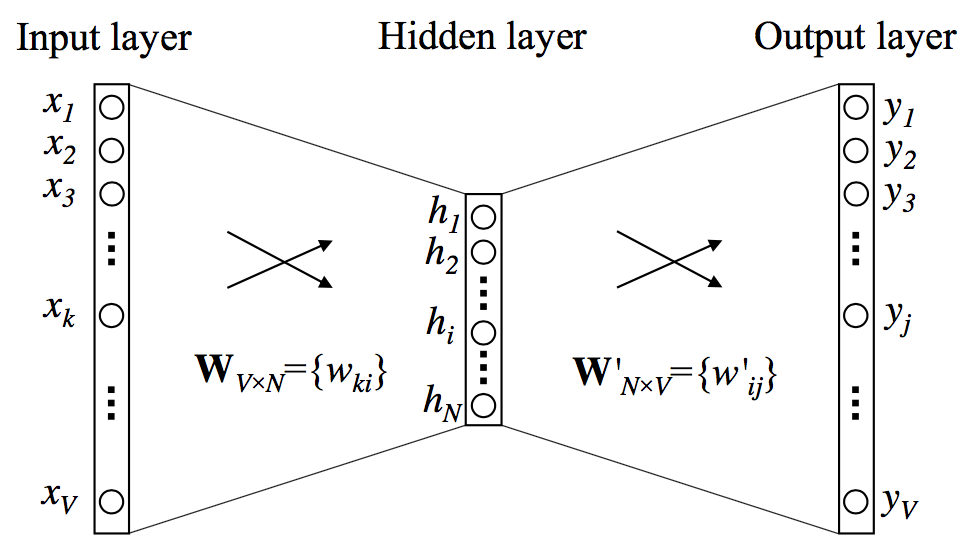
由One-hot编码的词向量经过隐含层编码降维,再解码升维后近似为原始编码,因此,需要最大化如下的似然。
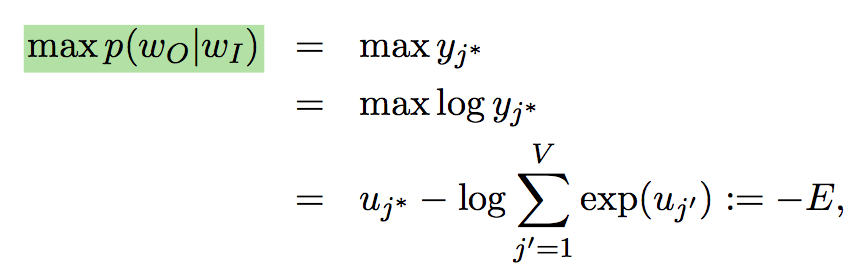
由神经元网络经典的反传误差的算法推导,网络结构参数的递推公式如下。
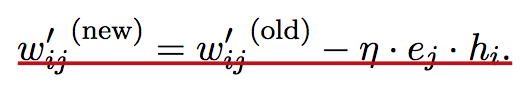
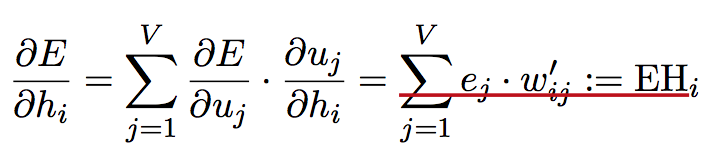
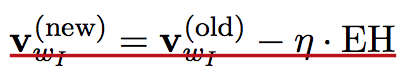
考虑到每个词的context,即窗口大小内共现的其他词,Word2vec可分为两种算法BOW和skip-grams,每个词根据当前的context,其词向量是窗口内所有词的词向量的均值。
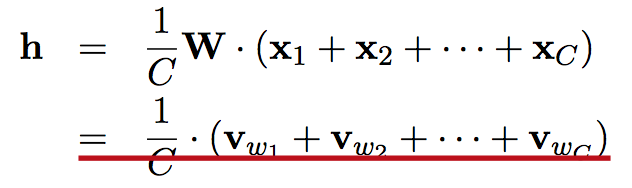
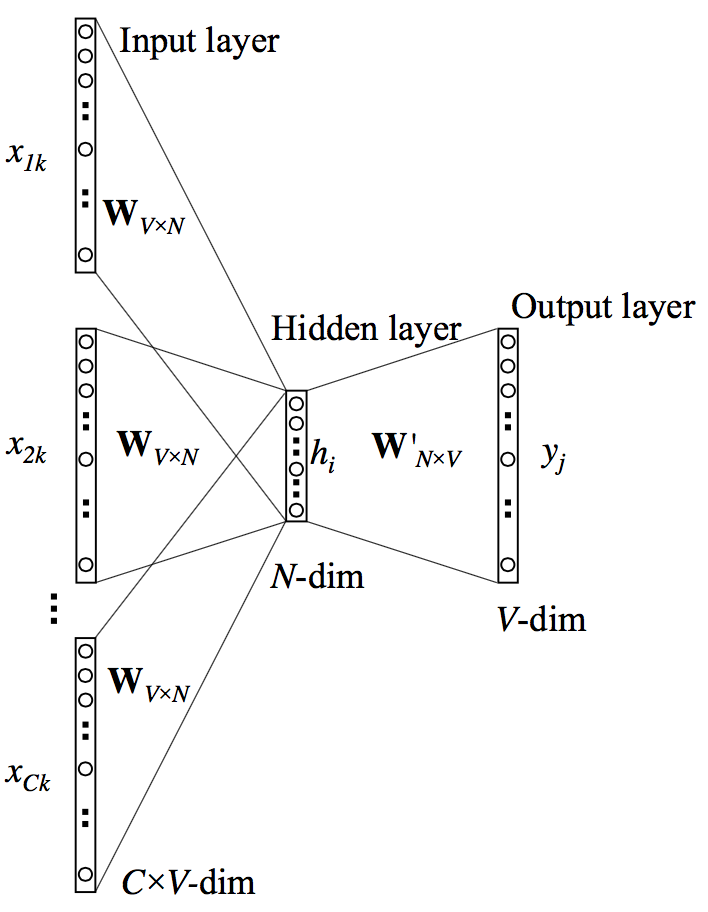
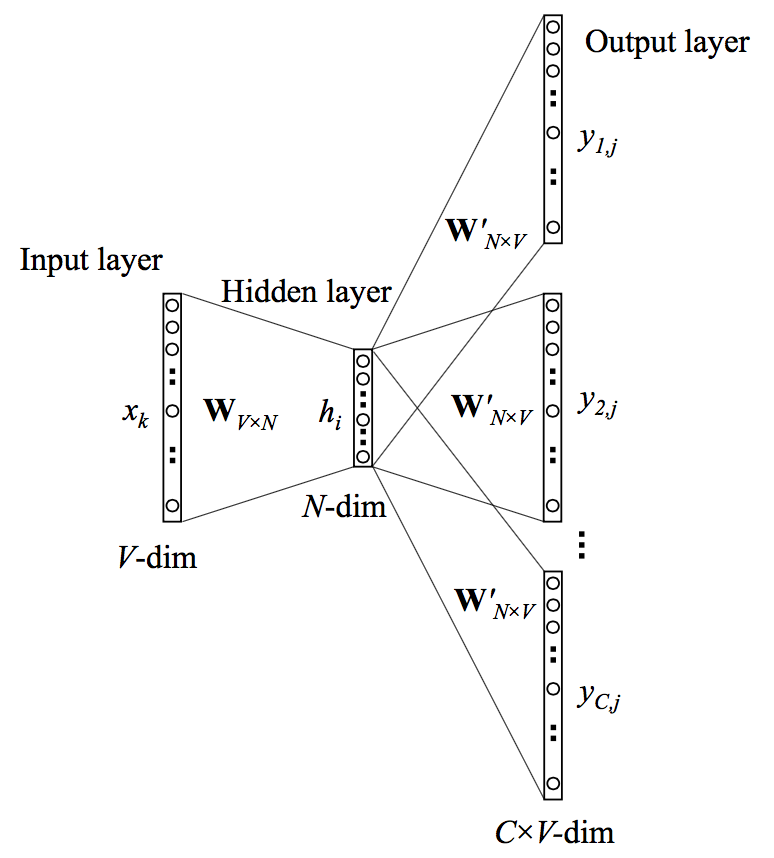
BOW和skip-grams的神经元网络结构如下,由此看出两者的区别在于输入和输出结构对调。
直接计算网络参数,由之前反传误差递推公式的推导,每次都需要更新所有词的词向量,计算效率低,提高计算效率,有两种方法,一种是通过建立Hierarchical Softmax,其核心思想是建立Huffman树,一种是通过Negative Sampling,减小所需更新的负样本的数量。
Huffman树如下所示,由于Huffman树某条支路上结点具有父子关系,相关性强,因此仅更新某条支路上所有结点的词向量,有效减小了计算复杂度。同时,根据Huffman树的特性,词频越大的词距离根结点越近,左右孩子结点的区分通过将词频大的结点作为左孩子结点,词频小的结点作为右孩子结点实现。由于Huffman树对应的Huffman编码具有不等长性质,因此更新次数能够得到优化。
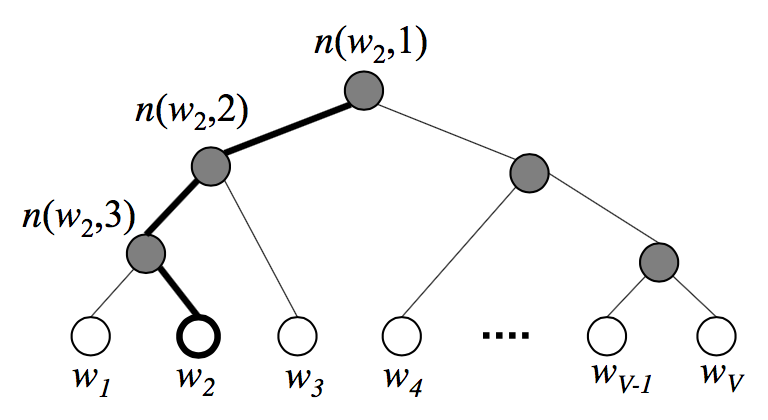
同样,为了减小需要更新词向量的词数,还能通过负采样,仅更新负样本的对应的词向量,减小了计算复杂度,其原理在于每个词的context中其他词出现的概率不同,只有那些共现概率高的词的影响更为强烈,对应需要抽样出的负样本,似然及参数更新计算过程如下。
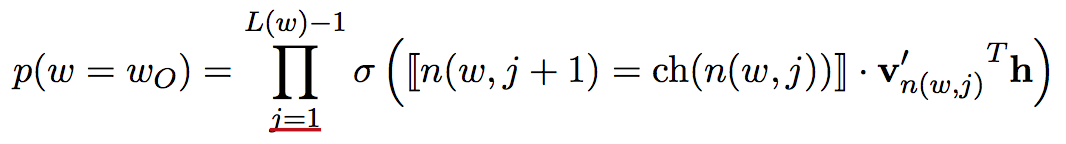
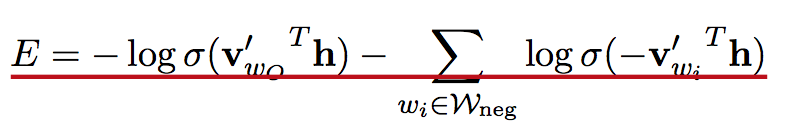
Word2vec核心函数解释
Word2vec的训练语料输入后按行进行训练。函数ReadWord读入流字符,通过判断换行符"\n"对样例进行划分。
void ReadWord(char *word, FILE *fin)
Word2vec通过建立哈希表vocab_hash对字符进行编码映射。函数AddWordToVocab视情况动态扩展空间。
const int vocab_hash_size = 30000000;
int *vocab_hash;
相关的util函数包括:
// Returns hash value of a word
int GetWordHash(char *word)
// Returns position of a word in the vocabulary; if the word is not found, returns -1
int SearchVocab(char *word)
// Reads a word and returns its index in the vocabulary
int ReadWordIndex(FILE *fin)
// Adds a word to the vocabulary
int AddWordToVocab(char *word)
// Sorts the vocabulary by frequency using word counts
void SortVocab()
// Reduces the vocabulary by removing infrequent tokens
void ReduceVocab()
前面提到,为了优化算法,提高计算效率,有两种方法,一种是通过建立Hierarchical Softmax,其核心思想是建立Huffman树,一种是Negative Sampling,减小更新负样本的数量。其中建立Huffman树的函数是CreateBinaryTree,其原理是根据词频创建Huffman树,词频越大的单词对应越短的Huffman编码。
// Create binary Huffman tree using the word counts
// Frequent words will have short uniqe binary codes
void CreateBinaryTree()
为了对负样本进行抽样,实现过程中建立了每个单词的能量分布表table,在负样本抽样中用到,此处直接看源码可能难以理解,相关注释如下。
void InitUnigramTable() {
int a, i;
long long train_words_pow = 0;
real d1, power = 0.75;
table = (int *)malloc(table_size * sizeof(int));
for (a = 0; a < vocab_size; a++) //遍历词汇表,统计能量总值train_words_pow,power为指数系数。
train_words_pow += pow(vocab[a].cn, power);
i = 0;
d1 = pow(vocab[i].cn, power) / (real)train_words_pow; //已遍历词的能量值占能量总值的比例
for (a = 0; a < table_size; a++) { //遍历table。a表示table的位置,i表示词汇表的位置
table[a] = i; //单词i占据table的位置a
//table反映的了单词能量的分布,单词能量越大对应占用table中的位置越多,越容易被抽样到
if (a / (real)table_size > d1) {
i++;
d1 += pow(vocab[i].cn, power) / (real)train_words_pow;
}
if (i >= vocab_siInitNetze) i = vocab_size - 1;
}
}
神经元网络参数保存在syn0、syn1、syn1neg,其中syn0数组存着Vocab的全部词向量,syn1数组存着Hierarchical Softmax的参数,syn1neg数组存着Negative Sampling的参数。
real *syn0, *syn1, *syn1neg, *expTable;
初始化和更新通过函数InitNet和TrainModelThread,其中TrainModelThread是线程调用函数,Word2vec的执行可基于多核,每个线程对应一段文本,根据线程id找到自己负责的文本的初始位置,线程函数执行之前,首先需要计算出按照词频排序的词汇表,以及每个单词的Huffman编码。
void InitNet()
void *TrainModelThread(void *id)
void TrainModel()
多线程创建调用函数如下。
for (a = 0; a < num_threads; a++) pthread_create(&pt[a], NULL, TrainModelThread, (void *)a);
for (a = 0; a < num_threads; a++) pthread_join(pt[a], NULL);
训练的具体过程如下,根据参数设定,确定是否建立Haffman树以及是否采用负采样进行优化,然后根据传播误差算法更新参数。
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) //扫描目标单词的左右单词
{
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) //layer1_size为词向量的维度
neu1[c] += syn0[c + last_word * layer1_size]; //计算向量和
}
if (hs) for (d = 0; d < vocab[word].codelen; d++) //开始遍历Huffman树
{
f = 0;
l2 = vocab[word].point[d] * layer1_size; //point记录Huffman的路径,找到当前节点,并算出偏移
// Propagate hidden -> output
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2];//计算内积
if (f <= -MAX_EXP) continue; //内积不在范围内直接丢弃
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]; //内积之后sigmoid函数
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;//偏导数的一部分
// Propagate errors output -> hidden 反向传播误差,从Huffman树传到隐藏
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output 更新当前内节点的向量
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c];
}
if (negative > 0) for (d = 0; d < negative + 1; d++) {
if (d == 0) {
target = word;
label = 1;
} else {
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size];
if (target == 0) target = next_random % (vocab_size - 1) + 1;
if (target == word) continue;
label = 0;
}
l2 = target * layer1_size;
f = 0;
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1neg[c + l2];
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * neu1[c];
}
// hidden -> in
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c];
}
}
相关连接
- http://code.google.com/p/word2vec/
- http://nlp.stanford.edu/projects/glove/