Relation Extraction
Relation Extraction
Relation Extraction
知识抽取任务在细节和可靠性上有不同的选择,但一般都包括两个普遍存在并且紧密关联的子任务:实体识 别和关系抽取。其中,关系抽取一般是指自动识别由一对概念和联系这对概念的关系构成的相关三元组。
Normally, we are interested in relations between entities, such as person, organization, and location. Examples of relations are person-affiliation and organization- location. Current state-of-the-art named entities recognizers (NER), such as (Bikel et al., 1999) and (Finkel et al., 2005), can automatically label data with high accuracy.
关系抽取的结果通常规范成(e1,e2,...,en)表示的多个实体的元组以及所属预先定义的关系集合中的类别r。通常关注的是二元关系,多元关系是二元关系的扩展。
A relation is defined in the form of a tuple t = (e1,e2,...,en) where the ei are entities in a pre-defined relation r within document D. Most relation extraction systems focus on extracting binary relations. Examples of binary relations include located-in(CMU, Pittsburgh), father-of(Manuel Blum, Avrim Blum). It is also possible to go to higher-order relations as well.
基于非结构化文本的实体关系抽取技术方法可以归纳为:基于模式匹配的关系抽取、基于词典驱动的关系抽取、基于机器学习的关系抽取、基于本体的关系抽取以及混合抽取方法。
其中基于机器学习的抽取方法可以粗分为Supervised和Semi-supervised。
Supervised Methods
基于有监督的学习方法可以等价为分类问题,及针对给出的任意两个实体,对其进行分类:是/否有关系,以及关系的类别。思路与常规的分类算法类似。
问题的表述如下。
The task of relation extraction is presented as a classification task.
Given a sentence S = w1,w2,..,e1..,wj,..e2,..,wn, where e1 and e2 are the entities, a mapping function f (.) can be given as
学习的目标是通过有标注数据训练得到分类器f。
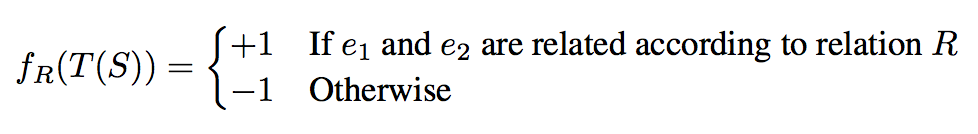
The function f (.) can be constructed as a discriminative classifier like Perceptron, Voted Perceptron or Support Vector Machines (SVMs).
分类器的学习问题可以进一步细化为特征工程问题,特征的好坏直接影响到分类器的最终准确率。
常用的特征通常来自于词性标注(POS tagging)以及语法树形结构(dependency parsing)等。
有监督的学习可以进一步细分成:(1) 特征方法(feature based methods) 和 (2) 核方法(kernel methods)。
基于特征的方法所使用的句法特征通常包括一下几个方面:
- the entities themselves
- the types of the two entities
- word sequence between the entities
- number of words between the entities
- path in the parse tree containing the two entities
采用核方法的好处在于对原始的特征空间进行转换(例如将原来线性不可分的问题转换成线性可分的问题)。
The major advantage of kernel methods is they offer efficient solutions that allow us to explore a large (often exponential, or in some cases, infinite) feature space in polynominal computational time, without the need to explicitly represent the features.
下面的例子说明了利用核函数对特征空间进行转换的过程。
For example, a string x = cat can be expressed in a higher dimensional space of subsequences as follows:
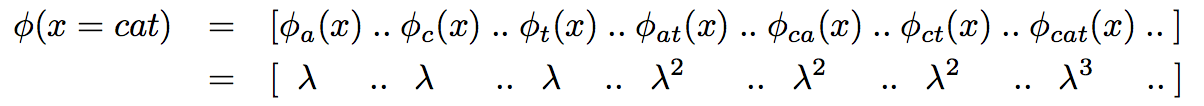
基于核函数的相似性计算如下。
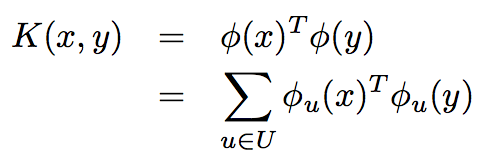
基于核函数的方法可以进一步细分成Bag of features Kernel和Tree Kernels两种,差异在于特征的抽取不同,Bag of features Kernel从原始线性序列的上下文中进行抽取,而Tree Kernels从语法树形结构中进行抽取。
Bag of features Kernel方法的解释如下。
(Bunescu & Mooney, 2005b) use the word-context around the named entities for extracting protein interactions from the MEDLINE abstracts. A sentence s = w1, ..., e1, ..., wi, ..., e2, ..., wn contain- ing related entities e1 and e2 can be described as s = sb e1 sm e2 sa. Here sb, sm and sa are portions of word-context before, middle and after the related entities respectively.
Tree Kernels方法的解释如下。
Compared to the previous approach, (Zelenko et al., 2003) replace the strings in the kernel with structured shallow parse trees built on the sentence. Now given a shallow parse, positive examples are constructed by enumerating the lowest subtrees which cover both the related entities. If a subtree does not cover the related entities, it is assigned a negative label.
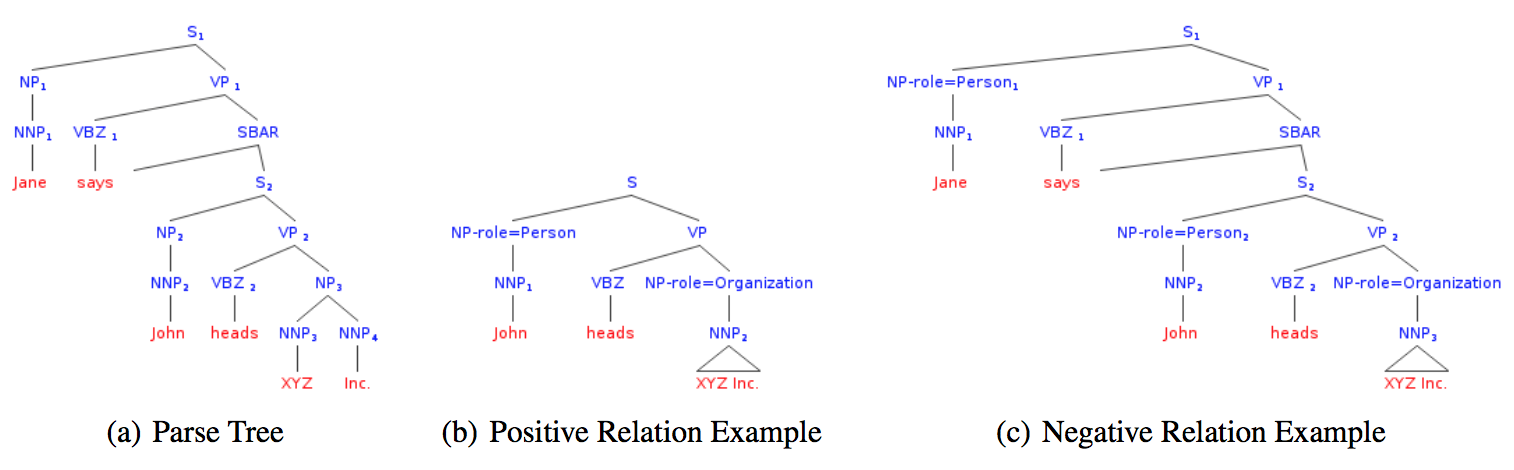
目前,经测试,基于dependency-path kernels的方法是所有基于kernel的方法中效果最好的。
Supervised Methods方法的局限性如下。
- These methods are difficult to extend to new entity-relation types for want of labeled data.
- Extensions to higher order entity relations are difficult as well.
- They are relatively computationally burdensome and do not scale well with increasing amounts of input data.
- Most of the methods described require pre-processed input data in the form of parse tree, dependency parse trees etc. The pre-processing stage is error prone and can hinder the performance of the system.
Semi-supervised Methods
通常人工标注数据集代价很大,不同于Supervised方法,Semi-supervised只需要人工指定少量抽取规则或一些种子数据即可,并在抽取过程中扩充数据集。
Only require a small set of tagged seed instances or a few hand-crafted extraction patterns per relation to launch the training process.
所以针对Semi-supervised方法的两个关键问题是:
- How to obtain seed automatically?
- What is a good seed?
DIPRE
Semi-supervised方法中的典型方法是DIPRE,其从网页中搜索符合预定规则的数据,对训练集进行扩充。
The system crawls the Internet to look for pages containing both instances of the seed. To learn patterns DIPRE uses a tuple of 6 elements [order,author,book,prefix,suffix,middle].
算法描述如下。

Snowball
Snowball类似于DIPRE,不同的是其将二元组表示成向量的形式,并通过相似性对二元组进行分组。
The classifier in Snowball is a pattern matching system like DIPRE, however, Snowball does not use exact matching. Snowball represents each tuple as a vector and uses a similarity function to group tuples. Snowball extracts tuples in form [prefix,orgnization,middle,location,suffix].
其计算过程如下,重点是相似性的定义。
Each wi is a term weight which is computed by the normalized frequency of that term in a given position. For example, term weight of token meet in the suffix is
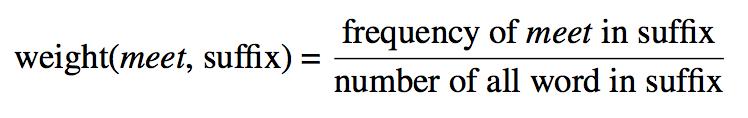
To group tuples which have the same (organization, location) representation but differ in prefix, suffix, and middle Snowball introduce the similarity function
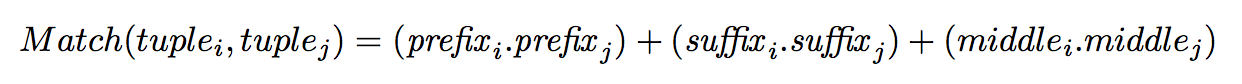
After grouping tuples into classes, Snowball induces a single tuple pattern P for each class which is a centroid vector tuple. Each pattern P is assigned a confidence score which measure the quality of a newly-proposed pattern
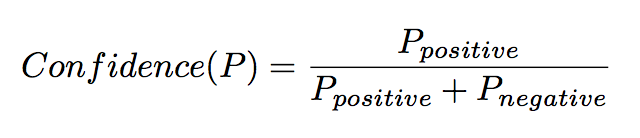
KnowItAll and TextRunner
不同于DIPRE和Snowball,KnowItAll和TextRunner会基于少量领域无关的抽取规则对数据进行标注。
Unlike DIPRE and Snowball, KnowItAll (Etzioni et al., 2005) is a large scale Web IE system that labels its own training examples using only a small set of domain independent extraction patterns.
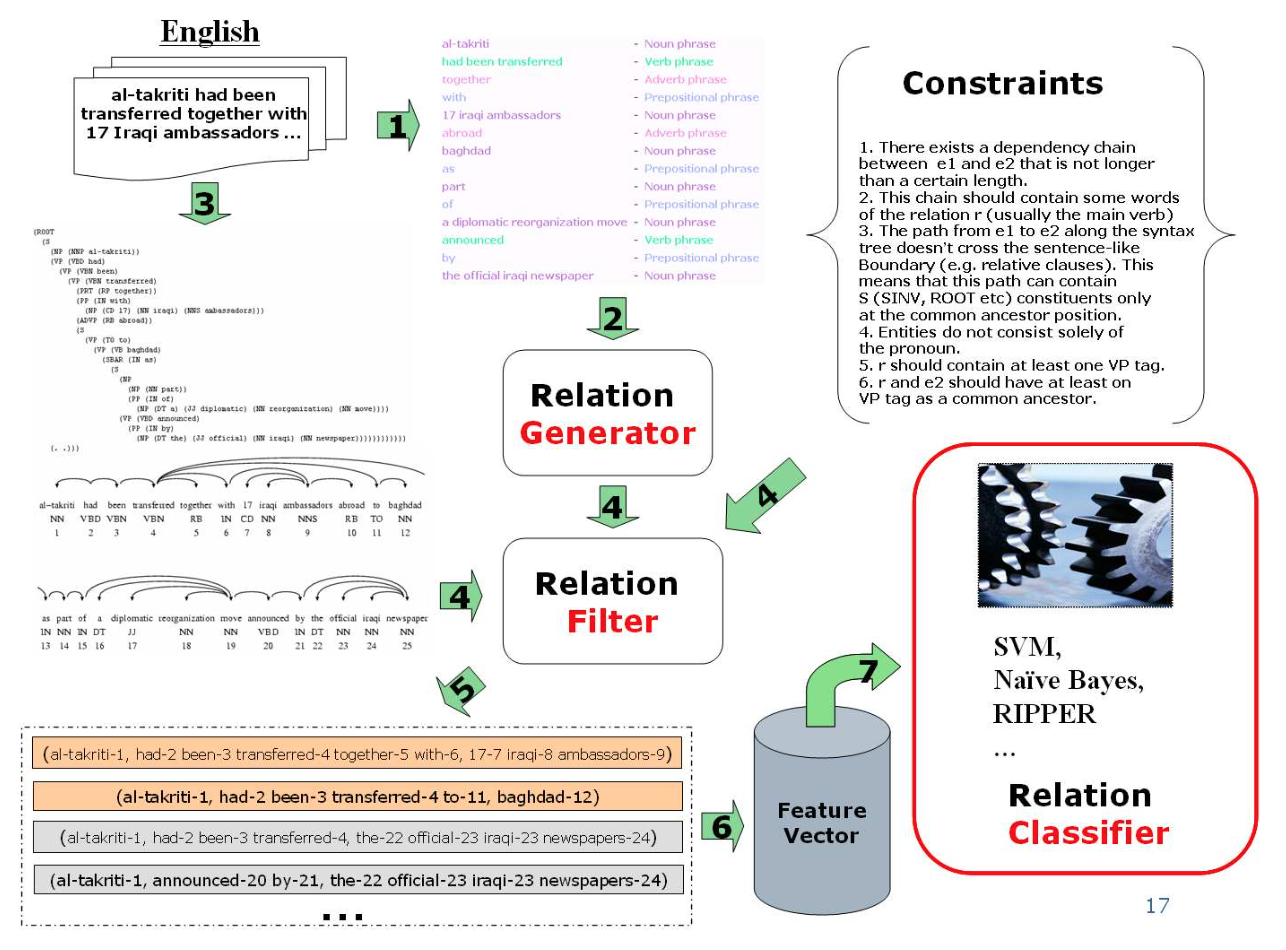
其整体算法流程如下所示。
The system contains three components which are 1) self-supervised Learner ; 2) single-pass Extractor; and 3) redundancy-based Assesor.
Semi-supervised Methods方法的局限性如下。
A major limitation of all systems studied here is that they are extracting relation on the sentence level. In fact, relations can span over sentences and even cross documents. It is not straightforward to modify algorithms described here to capture long range relations.
后续文章将详细分析上面提到的主要算法。
相关连接
- http://www.cs.cmu.edu/~nbach/papers/A-survey-on-Relation-Extraction.pdf