Keyphrase Extraction
Keyphrase Extraction
Keyphrase Extraction
关键短语抽取也是自然语言处理的关键问题之一,目的是从文章中抽取核心信息。
Automatic keyphrase extraction concerns "the automatic selection of important and topical phrases from the body of a document". In other words, its goal is to extract a set of phrases that are related to the main topics discussed in a given document.
关键短语抽取有助于文档的快速搜索,同时有助于文档的文摘、分类等工作。
Document keyphrases have enabled fast and accurate searching for a given document from a large text collection, and have exhibited their potential in improving many natural language processing (NLP) and information retrieval (IR) tasks, such as text summarization, text categorization, opinion mining, and document indexing.
Corpus-related factors
影响关键短语抽取难度的主要因素有以下几个,包括文章的长度、结构化、主题变化和关联等。
There are at least four corpus-related factors that affect the difficulty of keyphrase extraction.
- Length: it is harder to extract keyphrases from sci- entific papers, technical reports, and meeting tran- scripts than abstracts, emails, and news articles
- Structural consistency: In a structured document, there are certain locations where a keyphrase is most likely to appear
- Topic change: keyphrases typically appear not only at the beginning but also at the end of a document
- Topic correlation: keyphrases in a document are typically related to each other
Keyphrase Extraction Approaches
关键短语抽取的方法主要包含以下两个步骤。
- extracting a list of words/phrases that serve as candidate keyphrases using some heuristics
- determining which of these candidate keyphrases are correct keyphrases using supervised or unsupervised approaches
Selecting Candidate Words and Phrases
从文章中抽选候选词或短语的启发式算法包括。
- using a stop word list to remove stop words
- allowing words with certain part-of-speech tags to be candidate keywords
- allowing n-grams that appear in Wikipedia article titles to be candidates
- extracting n-grams or noun phrases that satisfy pre-defined lexico-syntactic pattern(s)
候选词或短语通常很多,因此需要基于启发式进行剪枝。
However, for a long document, the resulting list of candidates can be long. Consequently, different pruning heuristics have been designed to prune candidates that are unlikely to be keyphrases.
Supervised Approaches
有监督算法将关键短语抽取转化为候选词的分类问题(是否作为关键词/短语进行提取)。
The goal is to train a classifier on documents annotated with keyphrases to determine whether a candidate phrase is a keyphrase.
针对分类问题的算法包括各种分类算法。
Different learning algorithms have been used to train this classifier, including naive Bayes (Frank et al., 1999; Witten et al., 1999), decision trees (Turney, 1999; Turney, 2000), bagging (Hulth, 2003), boosting (Hulth et al., 2001), maximum entropy (Yih et al., 2006; Kim and Kan, 2009), multi-layer perceptron (Lopez and Romary, 2010), and support vector machines (Jiang et al., 2009; Lopez and Romary, 2010).
分类算法通常针对单个短语一次进行分类,然而短语间存在相关性。
Note that a binary classifier classifies each candidate keyphrase independently of the others, and consequently it does not allow us to determine which candidates are better than the others.
Motivated by this observation, Jiang et al. (2009) propose a ranking approach to keyphrase extraction, where the goal is to learn a ranker to rank two candidate keyphrases.
分类算法所基于的特征如下。
Within-Collection Features
- Statistical features: tf*idf; distance; supervised keyphraseness
- Structural features: how different instances of a candidate keyphrase are located in different parts of a document
- Syntactic features: the syntactic patterns of a candidate keyphrase
External Resource-Based Features
- Wikipedia-based keyphraseness: computed as a candidate’s document frequency multiplied by the ratio of the number of Wikipedia articles where the candidate appears as a link to the number of articles where it appears
- query log of a search engine: exploiting the observation that a candidate is potentially important if it was used as a search query
Unsupervised Approaches
无监督算法主要包含以下几种。
Graph-Based Ranking
基于图的排序算法。
Graph-Based Ranking build a graph from the input document and rank its nodes according to their importance using a graph-based ranking method (e.g., Brin and Page (1998)).
The edge weight is proportional to the syntactic and/or semantic relevance between the connected candidates.
A node’s score in the graph is defined recursively in terms of the edges it has and the scores of the neighboring nodes.
基于图的排序算法中典型的算法是TextRank。
TextRank (Mihalcea and Tarau, 2004) is one of the most well-known graph-based approaches to keyphrase extraction.
A set of keyphrases for a document should ideally cover the main topics discussed in it, but this instantiation does not guarantee that all the main topics will be represented by the extracted keyphrases.
Topic-Based Clustering
基于主题模型的聚类算法。
Topic-Based Clustering groups the candidate keyphrases in a document into topics, such that each topic is composed of all and only those candidate keyphrases that are related to that topic.
There are several motivations behind this topic-based clustering approach. First, a keyphrase should ideally be relevant to one or more main topic(s) discussed in a document. Second, the extracted keyphrases should be comprehensive in the sense that they should cover all the main topics in a document.
基于主题模型的聚类算法主要包括以下三种。
- KeyCluster: the underlying hypothesis is that each of these clusters corresponds to a topic covered in the document, and selecting the candidates close to the centroid of each cluster as keyphrases ensures that the resulting set of keyphrases covers all the topics of the document
- TopicalPageRank (TPR): It runs TextRank multiple times for a document, once for each of its topics induced by a Latent Dirichlet Allocation
- CommunityCluster: it extracts all candidate keyphrases from an important topic, assuming that a candidate that receives little focus in the text should still be extracted as a keyphrase as long as it is related to an important topic
Simultaneous Learning
同时学习算法(同时学习句子和词/短语的重要性/排序)。
A sentence is important if it contains important words, and important words appear in important sentences.
Two assumptions: (1) an important sentence is connected to other important sentences, and (2) an important word is linked to other important words, a TextRank-like assumption.
Language Modeling
语言模型算法。
LMA scores a candidate keyphrase based on two features, namely, phraseness (i.e., the ex- tent to which a word sequence can be treated as a phrase) and informativeness (i.e., the extent to which a word sequence captures the central idea of the document it appears in).
The foreground corpus is composed of the set of documents from which keyphrases are to be extracted. The background corpus is a large corpus that encodes general knowledge about the world (e.g., the Web).
语言模型算法主要基于两个核心指标:Phraseness和Informativeness,解释如下。
Phraseness, defined using the foreground LM, is calculated as the loss of information incurred as a result of assuming a unigram LM (i.e., conditional independence among the words of the phrase) instead of an n-gram LM (i.e., the phrase is drawn from an n-gram LM).
Informativeness is computed as the loss that results because of the assumption that the candidate is sampled from the background LM rather than the foreground LM.
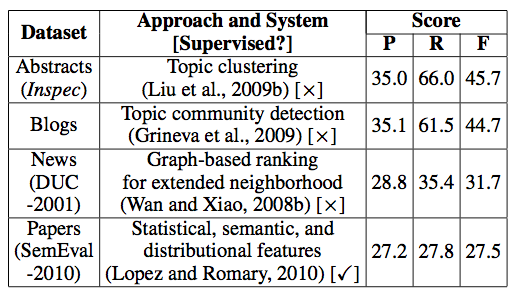
如下是常用的评估数据集和对应的系统。
The following table lists the best scores on some popular evaluation datasets and the corresponding systems.
相关连接
- http://www.hlt.utdallas.edu/~saidul/acl14.pdf
- hhttps://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/download/9414/9520
- http://research.microsoft.com/en-us/um/beijing/events/DL-WSDM-2015/paper.pdf
- http://jialu.cs.illinois.edu/paper/www2016-liu.pdf