General Purpose Sentence Realisation
General Purpose Sentence Realisation
General Purpose Sentence Realisation
句子生成(或称为表层实现)是指从给定的抽象语义逻辑生成符合句法、词形、拼写的句子。
Sentence generation, or surface realisation can be described as the problem of producing syntactically, morphologically, and orthographically correct sentences from a given semantic or syntactic representation.
常用的句法解析或生成方法包括:Lexical Functional Grammar (LFG), Head-Driven Phrase Structure Grammar (HPSG), Combinatory Categorial Grammar (CCG), Tree Adjoining Grammar (TAG)等。句子生成(表层实现)的自动化,所采用的方法主要基于generate-and-select paradigm。这种方法首先生成一系列可能的形式,然后基于概率模型选择出其中最可能的一个。
Over the last decade, probabilistic models have become widely used in the field of natural language generation (NLG), often in the form of a realisation ranker in a two-stage generation architecture. The two-stage methodology is characterised by a separation between generation and selection, in which rule-based methods are used to generate a space of possible paraphrases, and statistical methods are used to select the most likely realisation from the space.
排序算法中的概率模型通常包含以下两种:N-gram模型和Log-linear模型。
- N-gram language models over different units, such as word-level bigram/trigram models (Bangalore and Rambow, 2000; Langkilde, 2000), or factored language models integrated with syntactic tags (White et al., 2007).
- Log-linear models with different syntactic and semantic features (Velldal and Oepen, 2005; Nakanishi et al., 2005; Cahill et al., 2007).
To date, however, probabilistic models learning direct mappings from generation input to surface strings, without the effort to construct a grammar, have rarely been explored.
Lexical Functional Grammar
词汇功能语法(Lexical Functional Grammar)是一种形式语法,是美国计算语言学家布列斯南(Bresnan, J.)和卡普兰(Kaplan, R.)提出的一种用于自然语言处理的形式语法。
关于词汇功能语法的详细说明可以参考如下。
http://d.wanfangdata.com.cn/Periodical/kjxx-xsb200819061
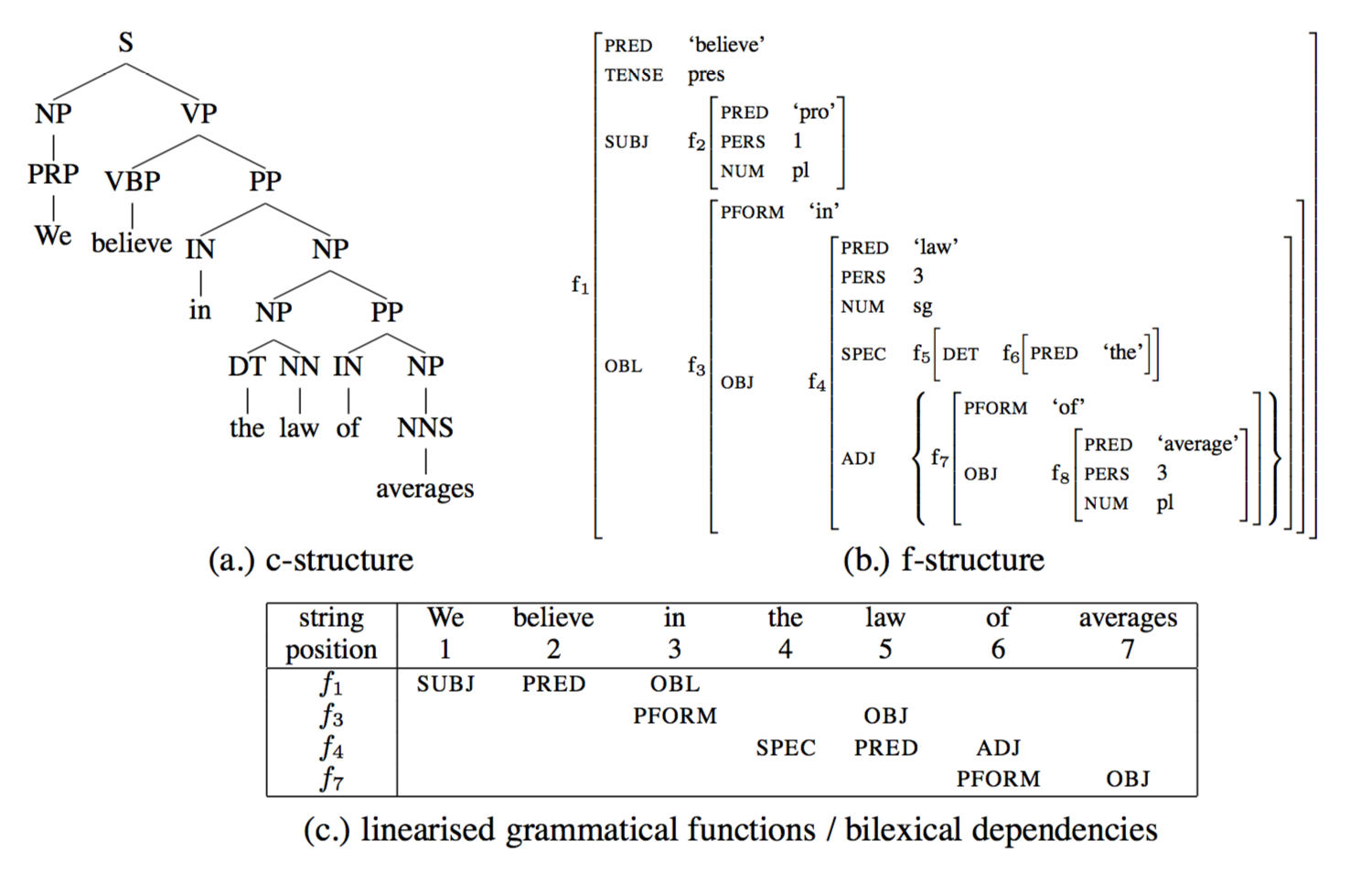
Lexical Functional Grammar (Kaplan and Bresnan, 1982) is a constraint-based grammar formalism which postulates (minimally) two levels of representation: c(onstituent)-structure and f(unctional)-structure.
词汇功能语法主要包括C-structure和F-structure两种模式,分别从不同的角度对句子进行描述。
A c-structure is a conventional phrase structure tree and captures surface grammatical configurations. The f-structure encodes more abstract functional relations like SUBJ(ect), OBJ(ect) and ADJ(unct).
F-structure中的属性主要包含两大类:语法结构(描述predicate and dependents之间的关系),原子特征(描述词本身的特性)
F-structures are hierarchical attribute-value matrix representations of bilexical labelled dependencies, approximating to basic predicate-argument/adjunct structures. Attributes in f-structure come in two different types:
- Grammatical Functions (GFs) indicate the relationship between the predicate and dependents. GFs can be divided into:
arguments are subcategorised for by the predicate, such as SUBJ(ect), OBJ(ect), and thus can only occur once in each local f-structure.
modifiers like ADJ(unct), COORD(inate) are not subcategorised for by the predicate, and can occur any number of times in a local f-structure. - Atomic-valued features describe linguistic properties of the predicate, such as TENSE, ASPECT, MOOD, PERS, NUM, CASE etc.
Generation from F-Structures
生成F-Structures的已有方法主要包括以下。
Work on generation in LFG generally assumes that the generation task is to determine the set of strings of the language that corresponds to a specified f-structure, given a particular grammar (Kaplan and Wedekind, 2000).
- The XLE generates sentences from f-structures according to parallel handcrafted grammars for English, French, German, Norwegian, Japanese, and Urdu.
- Cahill et al. (2007) describe a two-stage, log-linear generation model.
- Cahill and van Genabith (2006) and Hogan et al. (2007) present a chart generator using wide-coverage PCFG-based LFG approximations automatically acquired from treebanks (Cahill et al., 2004).
Dependency-Based Generation
F-Structures的生成可以看成句法解析的逆过程。
Traditional LFG generation models can be regarded as the reverse process of parsing, and use bi-directional f-structure-annotated CFG rules.
Following the methodology in (Cahill et al., 2004; Guo et al., 2007), automatically convert the English PennII treebank and the Chinese Penn Treebank (Xue et al., 2005) into f-structure banks.
F-structures是无向的,为了生成F-structures,首先需要对GFs进行线性化。
F-structures such as (b.) are unordered, i.e. they do not carry information on to the relative surface order of local GFs. In order to generate a string from an f-structure, need to linearise the GFs (at each level of embedding) in the f-structure (and map lemmas and features to surface forms).
对GFs进行线性化可采用n-gram模型。
Using n-gram models over GFs. In order to build the n-gram models, linearise the f-structures automatically produced from treebanks by associating the numerical string position (word offset from start of the sentence) with the predicate in each local f-structure, producing GF sequences as in (c.).
采用n-gram模型的好处在于其通用性。
Even though the n-gram models are exemplified using LFG f-structures, they are general-purpose models and thus suitable for any bilexical labelled dependency (Nivre, 2006) or predicate-argument type representations, such as the labelled feature-value structures used in HALogen and the functional descriptions in the FUF/SURGE system.
N-Gram Models
Basic N-Gram Model
基本N-Gram模型算法描述如下。
The primary task of a sentence generator is to determine the linear order of constituents and words, represented as lemmas in predicates in f-structures. At a particular local f-structure, the task of generating a string covered by the local f-structure is equivalent to linearising all the GFs present at that local f-structure.
Given a (sub-) f-structure F containing m GFs, the n-gram model searches for the best surface sequence S1m=s1...sm generated by the GF linearisation GF1m = GF1 ...GFm, which maximises the probability P(GF1m). Using n-gram models, P(GF1m) is calculated according to Eq.(1).
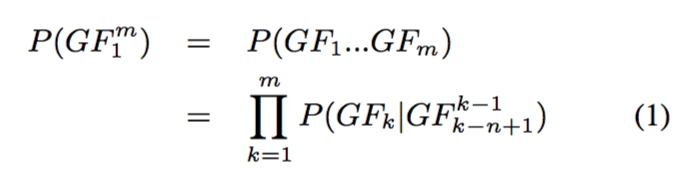
Factored N-Gram Models
Integrate contextual and fine-grained lexical information into several factored models.
为了进一步细化,可以基于词汇信息对模型进行分解,主要考虑下面三个维度的信息。
Eq.(2) additionally conditions the probability of the n-gram on the parent GF label of the current local f-structure fi, Eq.(3) on the instantiated PRED of the local f-structure fi, and Eq.(4) lexicalises the model, where each GF is augmented with its own predicate lemma.
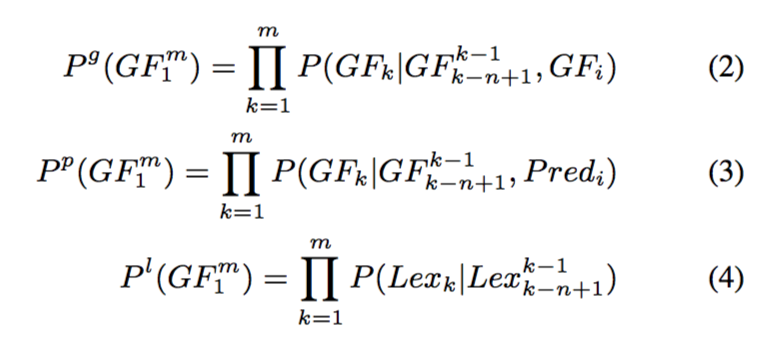
由于数据的稀疏性,可以采用线性插值对数据进行平滑。
To avoid data sparseness, the factored n-gram models P f are smoothed by linearly interpolating the basic n-gram model P, as in Eq.(5).
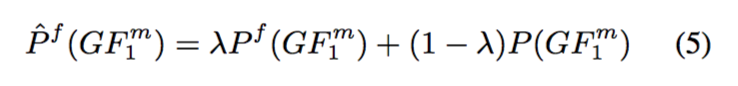
除了词汇化,还可以结合以下两个模型。
Additionally, the lexicalised n-gram models P are combined with the other two models conditioned on the additional parent GF Pg and PRED Pp, as shown in Eqs. (6) & (7), respectively.
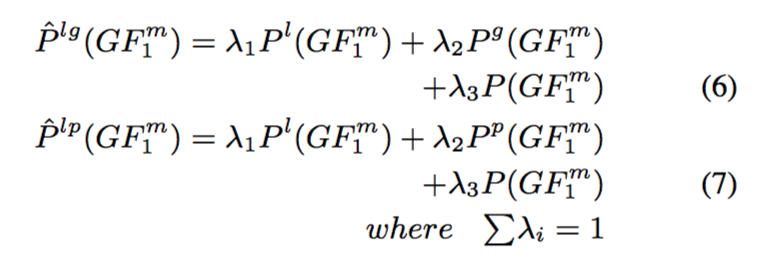
Generation Algorithm
生成算法描述如下。为了简化模型,可以增加独立性假设。
Our basic n-gram based generation model implements the simplifying assumption that linearisation at one sub-f-structure is independent of linearisation at any other sub-f-structures.
In summary, given an input f-structure f, the core algorithm of the generator recursively traverses f and at each sub-f-structure fi:
- instantiates the local predicate at fi and performs inflections/declensions if necessary
- calculates the GF linearisations present at fi by n-gram models
- finds the most probable GF sequence among all possibilities by Viterbi search
- generates the string covered by fi according to the linearised GFs
相关连接
- https://www.aclweb.org/anthology/C/C08/C08-1038.pdf