SyntaxNet安装笔记
SyntaxNet安装笔记
SyntaxNet安装笔记
谷歌宣布开放自然语言理解软件SyntaxNet的源代码,将其作为该公司TensorFlow开源机器学习库的一部分。 这个名为Parsey McParseface的句法分析程序可以自动判断某个单词是名词、动词还是形容词。 它是目前全球同类程序中准确度最高的一款,甚至可以与人类语言学家媲美。
https://github.com/qiangsiwei/models/tree/master/syntaxnet
SyntaxNet安装过程如下(基于Mac OS X)。
Install bazel
由于WORKSPACE issue,需要安装0.2.2版本而不是0.2.2b
# 1. Install JDK 8
# 2. Install XCode command line tools
# $ sudo gcc --version
# Download bazel from https://github.com/bazelbuild/bazel/releases
chmod +x bazel-version-installer-os.sh
./bazel-version-installer-os.sh --user
export PATH="$PATH:$HOME/bin"
Install swig
brew install swig
Install protocol buffers, with a version supported by TensorFlow
pip freeze | grep protobuf1
pip install -U protobuf==3.0.0b2
Install asciitree, to draw parse trees on the console for the demo
pip install asciitree
Build SyntaxNet
git clone --recursive https://github.com/tensorflow/models.git
cd models/syntaxnet/tensorflow
./configure
cd ..
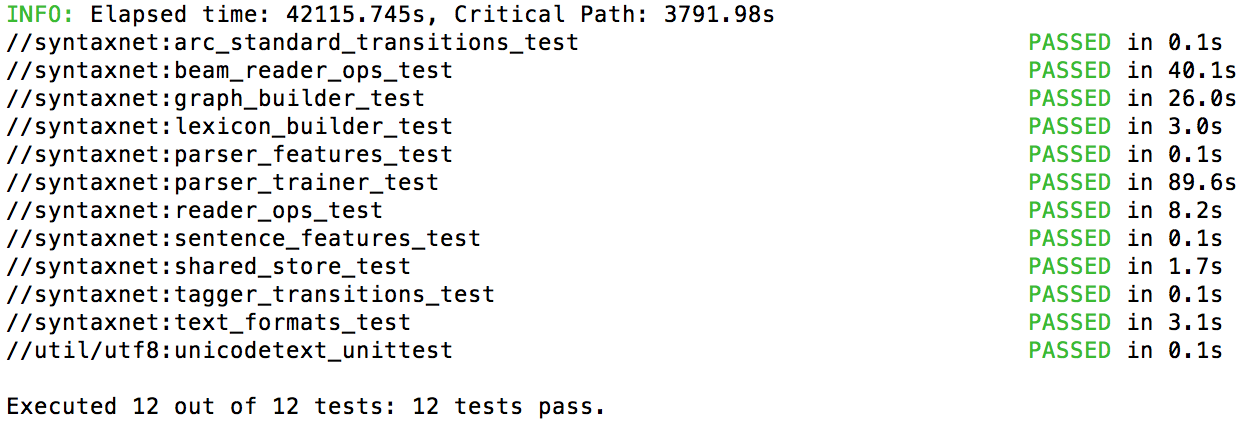
bazel test --linkopt=-headerpad_max_install_names syntaxnet/... util/utf8/...
显示如下表示安装成功
运行syntaxnet/demo.sh进行测试
echo 'Bob brought the pizza to Alice.' | syntaxnet/demo.sh
输出结果如下
I syntaxnet/term_frequency_map.cc:101] Loaded 46 terms from syntaxnet/models/parsey_mcparseface/label-map.
I syntaxnet/embedding_feature_extractor.cc:35] Features: stack.child(1).label stack.child(1).sibling(-1).label stack.child(-1).label stack.child(-1).sibling(1).label stack.child(2).label stack.child(-2).label stack(1).child(1).label stack(1).child(1).sibling(-1).label stack(1).child(-1).label stack(1).child(-1).sibling(1).label stack(1).child(2).label stack(1).child(-2).label; input.token.tag input(1).token.tag input(2).token.tag input(3).token.tag stack.token.tag stack.child(1).token.tag stack.child(1).sibling(-1).token.tag stack.child(-1).token.tag stack.child(-1).sibling(1).token.tag stack.child(2).token.tag stack.child(-2).token.tag stack(1).token.tag stack(1).child(1).token.tag stack(1).child(1).sibling(-1).token.tag stack(1).child(-1).token.tag stack(1).child(-1).sibling(1).token.tag stack(1).child(2).token.tag stack(1).child(-2).token.tag stack(2).token.tag stack(3).token.tag; input.token.word input(1).token.word input(2).token.word input(3).token.word stack.token.word stack.child(1).token.word stack.child(1).sibling(-1).token.word stack.child(-1).token.word stack.child(-1).sibling(1).token.word stack.child(2).token.word stack.child(-2).token.word stack(1).token.word stack(1).child(1).token.word stack(1).child(1).sibling(-1).token.word stack(1).child(-1).token.word stack(1).child(-1).sibling(1).token.word stack(1).child(2).token.word stack(1).child(-2).token.word stack(2).token.word stack(3).token.word
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: labels;tags;words
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 32;32;64
I syntaxnet/term_frequency_map.cc:101] Loaded 49 terms from syntaxnet/models/parsey_mcparseface/tag-map.
I syntaxnet/term_frequency_map.cc:101] Loaded 46 terms from syntaxnet/models/parsey_mcparseface/label-map.
I syntaxnet/embedding_feature_extractor.cc:35] Features: input.digit input.hyphen; input.prefix(length="2") input(1).prefix(length="2") input(2).prefix(length="2") input(3).prefix(length="2") input(-1).prefix(length="2") input(-2).prefix(length="2") input(-3).prefix(length="2") input(-4).prefix(length="2"); input.prefix(length="3") input(1).prefix(length="3") input(2).prefix(length="3") input(3).prefix(length="3") input(-1).prefix(length="3") input(-2).prefix(length="3") input(-3).prefix(length="3") input(-4).prefix(length="3"); input.suffix(length="2") input(1).suffix(length="2") input(2).suffix(length="2") input(3).suffix(length="2") input(-1).suffix(length="2") input(-2).suffix(length="2") input(-3).suffix(length="2") input(-4).suffix(length="2"); input.suffix(length="3") input(1).suffix(length="3") input(2).suffix(length="3") input(3).suffix(length="3") input(-1).suffix(length="3") input(-2).suffix(length="3") input(-3).suffix(length="3") input(-4).suffix(length="3"); input.token.word input(1).token.word input(2).token.word input(3).token.word input(-1).token.word input(-2).token.word input(-3).token.word input(-4).token.word
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: other;prefix2;prefix3;suffix2;suffix3;words
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 8;16;16;16;16;64
I syntaxnet/term_frequency_map.cc:101] Loaded 64036 terms from syntaxnet/models/parsey_mcparseface/word-map.
INFO:tensorflow:Building training network with parameters: feature_sizes: [12 20 20] domain_sizes: [ 49 51 64038]
INFO:tensorflow:Created variable step:0 with shape () and init <function OnesInitializer at 0x107f09230>
I syntaxnet/term_frequency_map.cc:101] Loaded 64036 terms from syntaxnet/models/parsey_mcparseface/word-map.
I syntaxnet/term_frequency_map.cc:101] Loaded 49 terms from syntaxnet/models/parsey_mcparseface/tag-map.
INFO:tensorflow:Created variable embedding_matrix_0:0 with shape (49, 32) and init <function _initializer at 0x107f09578>
INFO:tensorflow:Building training network with parameters: feature_sizes: [2 8 8 8 8 8] domain_sizes: [ 5 10665 10665 8970 8970 64038]
INFO:tensorflow:Created variable step:0 with shape () and init <function OnesInitializer at 0x107e09230>
INFO:tensorflow:Created variable embedding_matrix_0:0 with shape (5, 8) and init <function _initializer at 0x107e095f0>
INFO:tensorflow:Created variable embedding_matrix_1:0 with shape (51, 32) and init <function _initializer at 0x108982ed8>
INFO:tensorflow:Created variable embedding_matrix_2:0 with shape (64038, 64) and init <function _initializer at 0x1089f5a28>
INFO:tensorflow:Created variable embedding_matrix_1:0 with shape (10665, 16) and init <function _initializer at 0x108d03ed8>
INFO:tensorflow:Created variable weights_0:0 with shape (2304, 512) and init <function _initializer at 0x108c6af50>
INFO:tensorflow:Created variable embedding_matrix_2:0 with shape (10665, 16) and init <function _initializer at 0x108d75a28>
INFO:tensorflow:Created variable bias_0:0 with shape (512,) and init <function _initializer at 0x107f09320>
INFO:tensorflow:Created variable embedding_matrix_3:0 with shape (8970, 16) and init <function _initializer at 0x108deaf50>
INFO:tensorflow:Created variable weights_1:0 with shape (512, 512) and init <function _initializer at 0x108d01488>
INFO:tensorflow:Created variable bias_1:0 with shape (512,) and init <function _initializer at 0x107f09320>
INFO:tensorflow:Created variable embedding_matrix_4:0 with shape (8970, 16) and init <function _initializer at 0x108e6bd70>
INFO:tensorflow:Created variable softmax_weight:0 with shape (512, 93) and init <function _initializer at 0x108d93d70>
INFO:tensorflow:Created variable embedding_matrix_5:0 with shape (64038, 64) and init <function _initializer at 0x108ec3a28>
INFO:tensorflow:Created variable softmax_bias:0 with shape (93,) and init <function zeros_initializer at 0x106f988c0>
INFO:tensorflow:Created variable weights_0:0 with shape (1040, 64) and init <function _initializer at 0x108f3af50>
INFO:tensorflow:Created variable bias_0:0 with shape (64,) and init <function _initializer at 0x107e09320>
INFO:tensorflow:Created variable softmax_weight:0 with shape (64, 49) and init <function _initializer at 0x108fd1488>
INFO:tensorflow:Created variable softmax_bias:0 with shape (49,) and init <function zeros_initializer at 0x10709b8c0>
I syntaxnet/term_frequency_map.cc:101] Loaded 46 terms from syntaxnet/models/parsey_mcparseface/label-map.
I syntaxnet/embedding_feature_extractor.cc:35] Features: stack.child(1).label stack.child(1).sibling(-1).label stack.child(-1).label stack.child(-1).sibling(1).label stack.child(2).label stack.child(-2).label stack(1).child(1).label stack(1).child(1).sibling(-1).label stack(1).child(-1).label stack(1).child(-1).sibling(1).label stack(1).child(2).label stack(1).child(-2).label; input.token.tag input(1).token.tag input(2).token.tag input(3).token.tag stack.token.tag stack.child(1).token.tag stack.child(1).sibling(-1).token.tag stack.child(-1).token.tag stack.child(-1).sibling(1).token.tag stack.child(2).token.tag stack.child(-2).token.tag stack(1).token.tag stack(1).child(1).token.tag stack(1).child(1).sibling(-1).token.tag stack(1).child(-1).token.tag stack(1).child(-1).sibling(1).token.tag stack(1).child(2).token.tag stack(1).child(-2).token.tag stack(2).token.tag stack(3).token.tag; input.token.word input(1).token.word input(2).token.word input(3).token.word stack.token.word stack.child(1).token.word stack.child(1).sibling(-1).token.word stack.child(-1).token.word stack.child(-1).sibling(1).token.word stack.child(2).token.word stack.child(-2).token.word stack(1).token.word stack(1).child(1).token.word stack(1).child(1).sibling(-1).token.word stack(1).child(-1).token.word stack(1).child(-1).sibling(1).token.word stack(1).child(2).token.word stack(1).child(-2).token.word stack(2).token.word stack(3).token.word
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: labels;tags;words
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 32;32;64
I syntaxnet/term_frequency_map.cc:101] Loaded 49 terms from syntaxnet/models/parsey_mcparseface/tag-map.
I syntaxnet/term_frequency_map.cc:101] Loaded 64036 terms from syntaxnet/models/parsey_mcparseface/word-map.
I syntaxnet/term_frequency_map.cc:101] Loaded 49 terms from syntaxnet/models/parsey_mcparseface/tag-map.
I syntaxnet/term_frequency_map.cc:101] Loaded 46 terms from syntaxnet/models/parsey_mcparseface/label-map.
I syntaxnet/embedding_feature_extractor.cc:35] Features: input.digit input.hyphen; input.prefix(length="2") input(1).prefix(length="2") input(2).prefix(length="2") input(3).prefix(length="2") input(-1).prefix(length="2") input(-2).prefix(length="2") input(-3).prefix(length="2") input(-4).prefix(length="2"); input.prefix(length="3") input(1).prefix(length="3") input(2).prefix(length="3") input(3).prefix(length="3") input(-1).prefix(length="3") input(-2).prefix(length="3") input(-3).prefix(length="3") input(-4).prefix(length="3"); input.suffix(length="2") input(1).suffix(length="2") input(2).suffix(length="2") input(3).suffix(length="2") input(-1).suffix(length="2") input(-2).suffix(length="2") input(-3).suffix(length="2") input(-4).suffix(length="2"); input.suffix(length="3") input(1).suffix(length="3") input(2).suffix(length="3") input(3).suffix(length="3") input(-1).suffix(length="3") input(-2).suffix(length="3") input(-3).suffix(length="3") input(-4).suffix(length="3"); input.token.word input(1).token.word input(2).token.word input(3).token.word input(-1).token.word input(-2).token.word input(-3).token.word input(-4).token.word
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: other;prefix2;prefix3;suffix2;suffix3;words
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 8;16;16;16;16;64
I syntaxnet/term_frequency_map.cc:101] Loaded 64036 terms from syntaxnet/models/parsey_mcparseface/word-map.
INFO:tensorflow:Processed 1 documents
INFO:tensorflow:Total processed documents: 1
INFO:tensorflow:num correct tokens: 0
INFO:tensorflow:total tokens: 7
INFO:tensorflow:Seconds elapsed in evaluation: 0.16, eval metric: 0.00%
INFO:tensorflow:Processed 1 documents
INFO:tensorflow:Total processed documents: 1
INFO:tensorflow:num correct tokens: 1
INFO:tensorflow:total tokens: 6
INFO:tensorflow:Seconds elapsed in evaluation: 0.63, eval metric: 16.67%
INFO:tensorflow:Read 1 documents
Input: Bob brought the pizza to Alice .
Parse:
brought VBD ROOT
+-- Bob NNP nsubj
+-- pizza NN dobj
| +-- the DT det
+-- to IN prep
| +-- Alice NNP pobj
+-- . . punct
相关连接
- https://github.com/qiangsiwei/models/tree/master/syntaxnet